LLM Router Latency Benchmark 2026: OpenAI Direct vs Router APIs
By Göran Sandahl -
When building LLM applications in 2026, developers face recurring performance questions that lack clear, data-driven answers. Does routing through an LLM gateway add latency compared to calling providers directly? How much does regional deployment matter versus model selection? Do different inference backends actually deliver the same performance for identical models?
We conducted comprehensive benchmarks across 10+ providers, routers, and backends to provide definitive answers to five critical questions that come up in every LLM deployment decision. Our tests measured real-world performance, not idealized lab conditions, using the same workloads production applications actually send.
Key Findings
Do LLM routers add latency?
No, OpenRouter was actually 70ms faster than OpenAI direct on time to first token (0.640s vs 0.712s) and Opper matched OpenAI directly within confidence intervals.
How much does AWS region selection matter?
Geography dominates model choice — Tokyo was 2x slower than Ireland (3.08s vs 1.61s), a bigger impact than switching model tiers.
Do different backends serving the same model perform equally?
No, there's a ~10x throughput difference across backends: Cerebras delivered 1,667 tokens/sec vs Berget's 174 tokens/sec for identical gpt-oss-120b.
Does prompt caching actually work in real conversations?
Yes, by turn 6 of multi-turn chats most backends ran 20–50% faster than without caching, even when APIs don't report cache hits.
Are "same model" outputs consistent across providers?
Yes, Claude Sonnet 4.5 responses were identical across Anthropic direct, AWS Bedrock, and Azure deployments.
How we tested LLM provider performance
Our benchmark focused on real-world scenarios rather than synthetic stress tests. We measured time to first token, tokens per second, and output consistency across multiple runs to account for natural variance. Each test used production-ready prompts and realistic conversation patterns to reflect what developers actually deploy.
For model selection, we chose GPT-4.1 and other established models rather than the latest releases because they're widely available across multiple APIs and providers. This let us make true apples-to-apples comparisons — newer models often aren't deployed consistently across all endpoints yet.
All test scripts, raw result files, and chart generation code are published at github.com/opper-ai/provider-benchmark. Every result file includes a SHA-256 hash of the benchmark script and the random seed used, so you can verify what code produced what numbers and reproduce any run.
1. Do LLM routers add latency? The router tax, tested
Question: Do router APIs add measurable latency versus going direct to the model vendor?
Test: 200 calls to GPT-4.1 against each of three destinations: OpenAI directly, OpenRouter, and Opper. We chose 200 calls because an earlier exploratory run showed us we'd need at least that many to reliably detect a 10% difference if one existed.
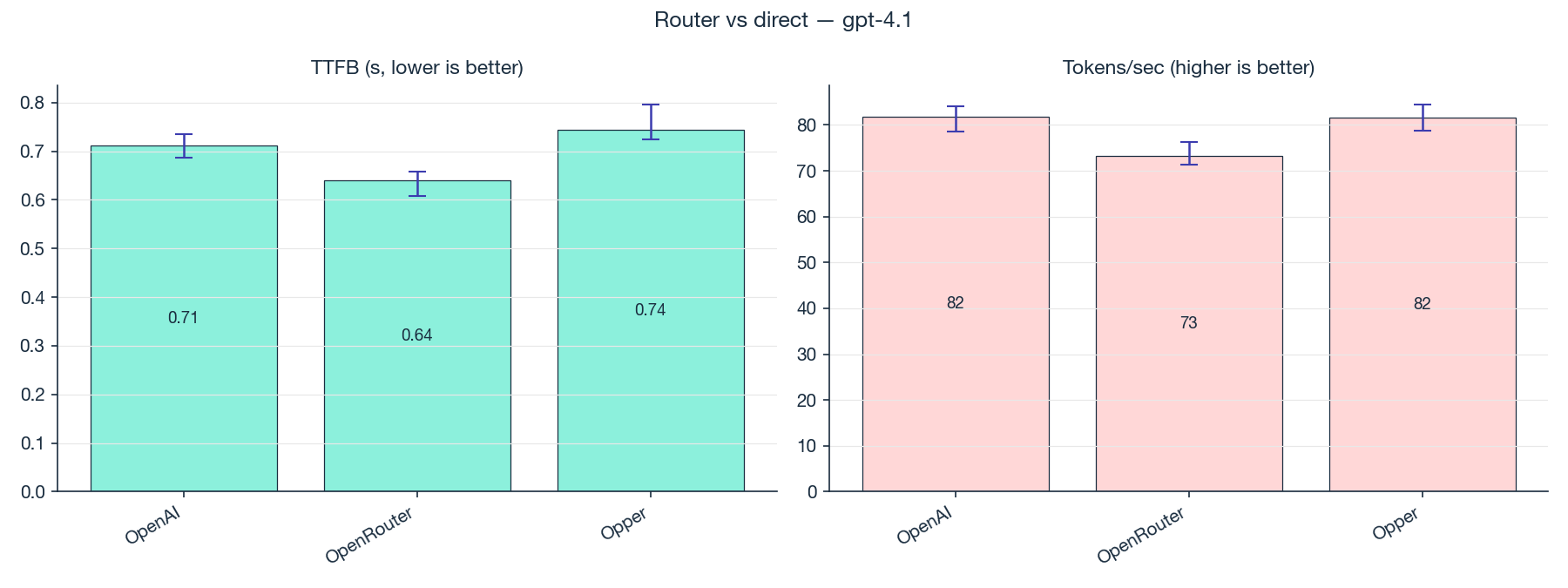
| Provider | Time to first token (95% CI) | Tokens per second (95% CI) |
|---|---|---|
| OpenAI direct | 0.712 [0.687, 0.735] s | 81.8 [78.6, 84.1] |
| OpenRouter | 0.640 [0.609, 0.657] s | 73.2 [71.3, 76.3] |
| Opper | 0.744 [0.725, 0.796] s | 81.5 [78.8, 84.5] |
With 200 calls per provider, the picture gets interesting. OpenRouter is actually the fastest to first token, 70ms ahead of OpenAI direct. That gap is real and outside the noise. A router being faster than the vendor on first-token latency directly contradicts the "routers are always slower" claim.
But each router makes a different tradeoff. OpenRouter trades throughput for that first-token speed: its tokens per second is about 10% lower than OpenAI, and that difference is also outside the noise. Opper matches OpenAI on both metrics: 30ms slower on first token (too close to call, the ranges overlap) and identical throughput.
So the blanket "router tax" claim doesn't hold. What's actually happening is that each router has its own performance profile. One is faster on first token but slower on throughput. Another matches the direct endpoint almost exactly. The right question isn't "is there a router tax?" but "what does this router trade off?"
Takeaway: routers don't uniformly add latency. Each one makes different tradeoffs. Test the specific router you're evaluating against the direct endpoint on the metrics that matter for your app, rather than assuming "direct is always faster."
2. Regional latency dominates model tier latency in 2026
Question: From a single vantage point in Europe, how much difference does AWS Bedrock region selection make on time to first token?
Test: Calls to claude-sonnet-4 across three Bedrock regions from a vantage point in Sweden.
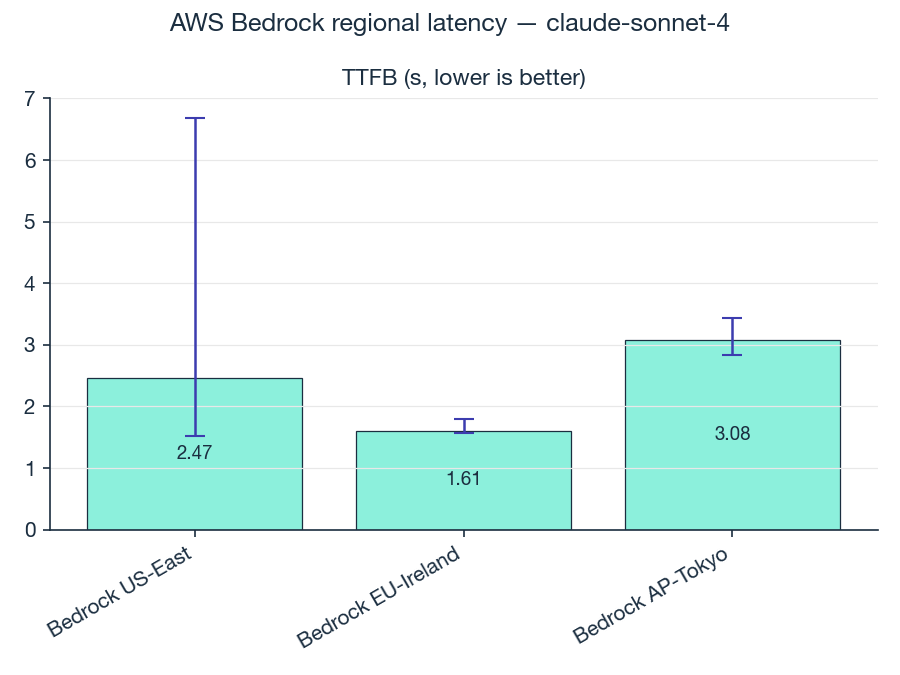
| Region | Time to first token |
|---|---|
| Bedrock EU-Ireland | 1.61 s |
| Bedrock US-East | 2.47 s |
| Bedrock AP-Tokyo | 3.08 s |
Tokyo is roughly 2x slower than Ireland. The gap between EU and Tokyo is well outside the noise.
The point isn't the gap itself, it's how it stacks against the other choices in your stack. The latency delta from picking Sonnet vs Haiku is typically smaller than the delta from picking the wrong region. If your users are in Europe and you're hitting us-east-1 because the SDK example used it, the win that actually matters is moving to eu-west-1, not switching model tiers.
Takeaway: geography is a bigger lever on user-perceptible latency than model tier is. Pick the region that matches your users before you optimize the model.
3. Inference backend matters more than model choice (10x throughput spread)
Question: How much does the inference backend matter when serving the same model?
Test: 30 calls to gpt-oss-120b across six different Opper-routed inference backends.
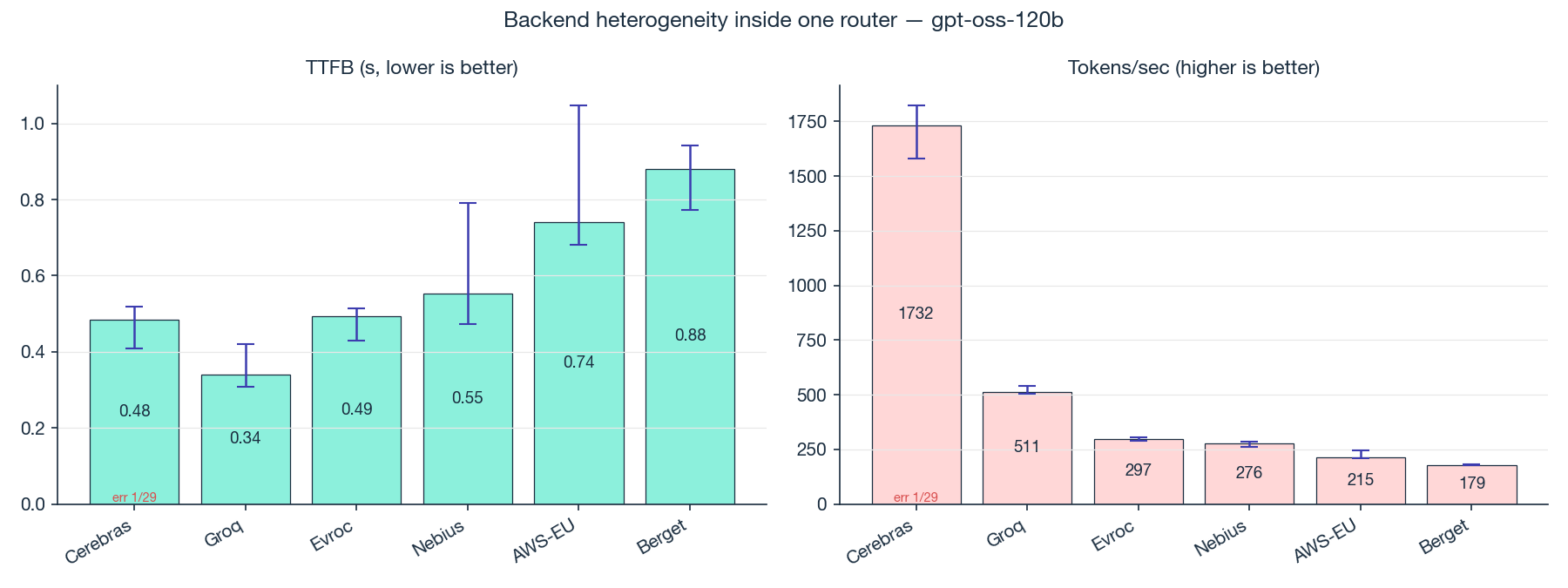
| Backend | Tokens per second (95% CI) |
|---|---|
| Cerebras | 1667 [1431, 1732] |
| Groq | 521 [511, 527] |
| AWS-EU | 311 [282, 322] |
| Evroc | 275 [273, 288] |
| Nebius | 217 [180, 242] |
| Berget | 174 [169, 177] |
A 10x spread in throughput across backends serving the exact same model. None of the ranges overlap, so the ranking is real.
The mechanism: Cerebras runs on a wafer-scale SRAM architecture with effectively zero-overhead prompt processing. Groq runs on a different in-memory chip generation. The rest are conventional GPU inference. Same model weights, very different serving hardware, with the throughput numbers to match.
Note: Performance is just one factor in backend selection. Providers like Berget offer important advantages in data sovereignty, EU hosting, and regulatory compliance that may outweigh raw throughput depending on your use case.
Takeaway: "I built on gpt-oss-120b" describes about 10% of what's actually happening to your users. The other 90% is which backend caught the request. If your provider lets you address backends explicitly (Opper does, OpenRouter does for some models), use it. The backend is a bigger lever than the model.
4. Does prompt caching work? More than the API tells you
Question: Does prompt caching actually save you time in a realistic multi-turn chat?
Test: For each provider, run a 6-turn conversation. Start with a large system prompt (~8,000 tokens). Each turn, send the full message history, let the model generate a real reply, append it to the history, send the now-grown prompt next turn. By turn 6 the prompt is about 17% larger than it started. Three independent runs per provider.
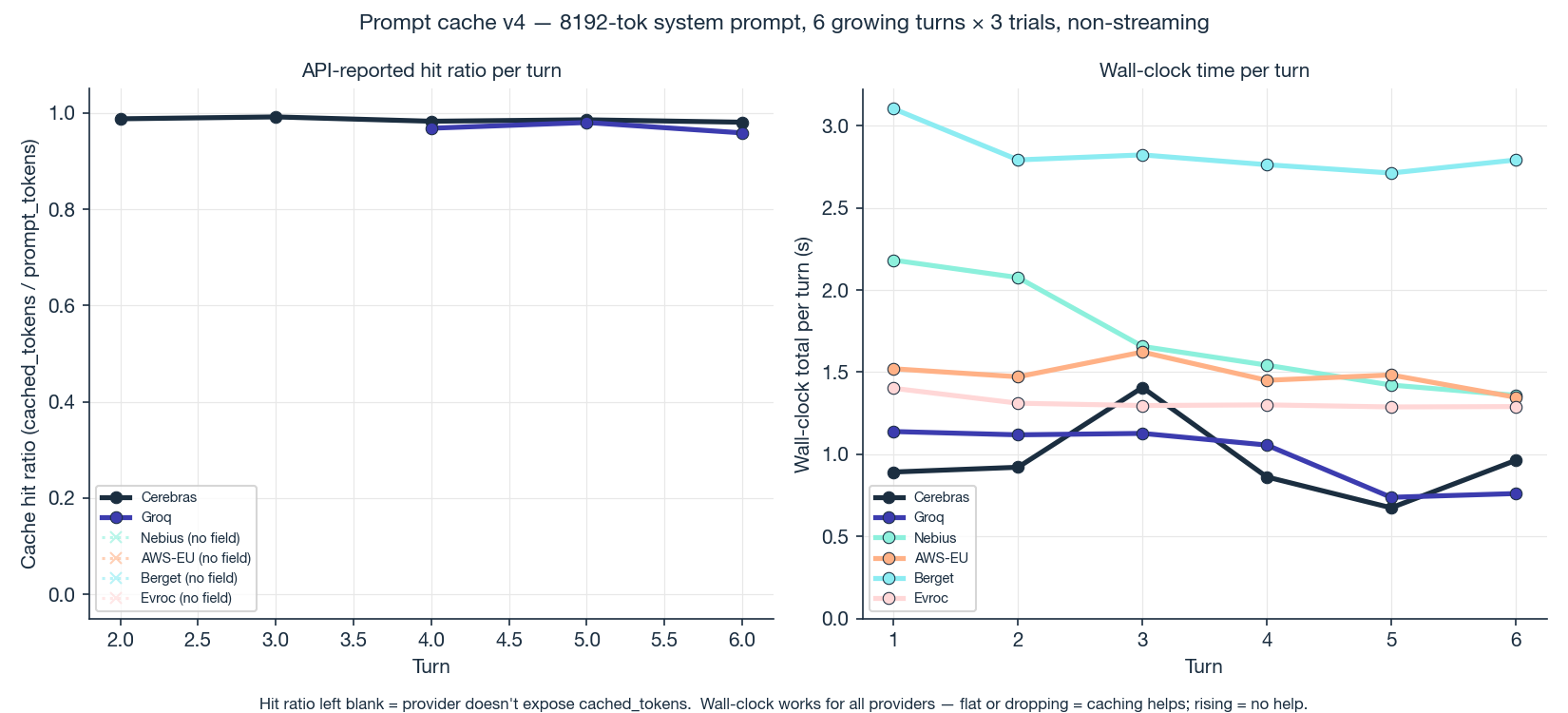
The intuitive way to read this data is to ask "did each turn get faster as the conversation went along?", and if you do that, the answer is uninspiring. Most providers stayed roughly flat.
That's the wrong question. The right question is: did response time stay flat as the prompt grew, instead of getting slower?
Each turn we cap the model's reply at 256 tokens, so the time spent generating the reply stays roughly constant. Anything else that changes turn over turn is the time the provider spends reading the prompt before it starts generating, and that should grow in lockstep with how much prompt we keep adding. By turn 6 the prompt is 17% bigger. Without caching, turn 6 should take about 17% longer. Instead, response time is flat, or even drops slightly. Holding flat against a growing prompt is the cache benefit. Caching is cancelling out the cost of the new tokens we keep adding each turn.
Here's the savings compared to what each turn would have taken without caching:
gpt-oss-120b across 6 backends:
| Backend | Turn 1 | Turn 6 | Turn 6 without caching | Savings |
|---|---|---|---|---|
| Cerebras | 1.35 s | 0.82 s | 1.58 s | 48% |
| Berget | 3.18 s | 2.59 s | 3.72 s | 30% |
| Nebius | 4.42 s | 3.71 s | 5.17 s | 28% |
| Evroc | 1.54 s | 1.38 s | 1.80 s | 23% |
| Groq | 1.13 s | 1.21 s | 1.32 s | 9% |
| AWS-EU | 1.28 s | 1.51 s | 1.50 s | ~0% |
And llama-3.3-70b-instruct across 4 backends:
| Backend | Turn 1 | Turn 6 | Turn 6 without caching | Savings |
|---|---|---|---|---|
| Berget | 7.96 s | 4.54 s | 9.31 s | 51% |
| Nebius | 9.01 s | 7.10 s | 10.54 s | 33% |
| Evroc | 4.64 s | 4.11 s | 5.43 s | 24% |
| Fireworks | 2.83 s | 2.86 s | 3.31 s | 14% |
By turn 6, most backends are running 20–40% faster than they would without caching. Caching is doing real, measurable work on every provider in the test, including the ones whose APIs don't say a word about it.
On instrumentation. Out of the 10 backend/model combinations we tested, only 3 report cache hits in the API response. The other 7 cache silently. You can prove they're caching by looking at the gap between expected and observed response time, but you can't audit it from the API itself. That's a real gap across the industry.
On the marketing numbers. The standard "prompt caching reduces time to first token by up to 80–85%" is consistent with our data. The marketing measures the prompt-reading phase in isolation, where caching does most of the heavy lifting. We measure the full request including generation, network, and queue. On a slow provider, prompt reading is most of the time, so cache savings show up clearly (20–40%). On a fast provider (Cerebras at 0.89s), prompt reading was already a small fraction, so the savings get absorbed. Both are true at the same time.
Takeaway: if you've built a long-context app, caching is almost certainly helping you, even on providers where the API doesn't say so. Don't pick on whether they expose cache reporting. Measure your actual workload and look at whether response time grows with prompt size or stays flat.
5. Is the same LLM model consistent across providers? Yes
Question: When a router exposes the same model through multiple upstream backends, are the outputs actually equivalent?
Test: claude-sonnet-4-5 is served by Opper through multiple upstream paths. We sent the same prompt 3 times to each and measured how much word overlap there was between each pair of responses. Then we compared that to how much a single backend overlaps with itself across runs, to separate real differences from normal model variation.
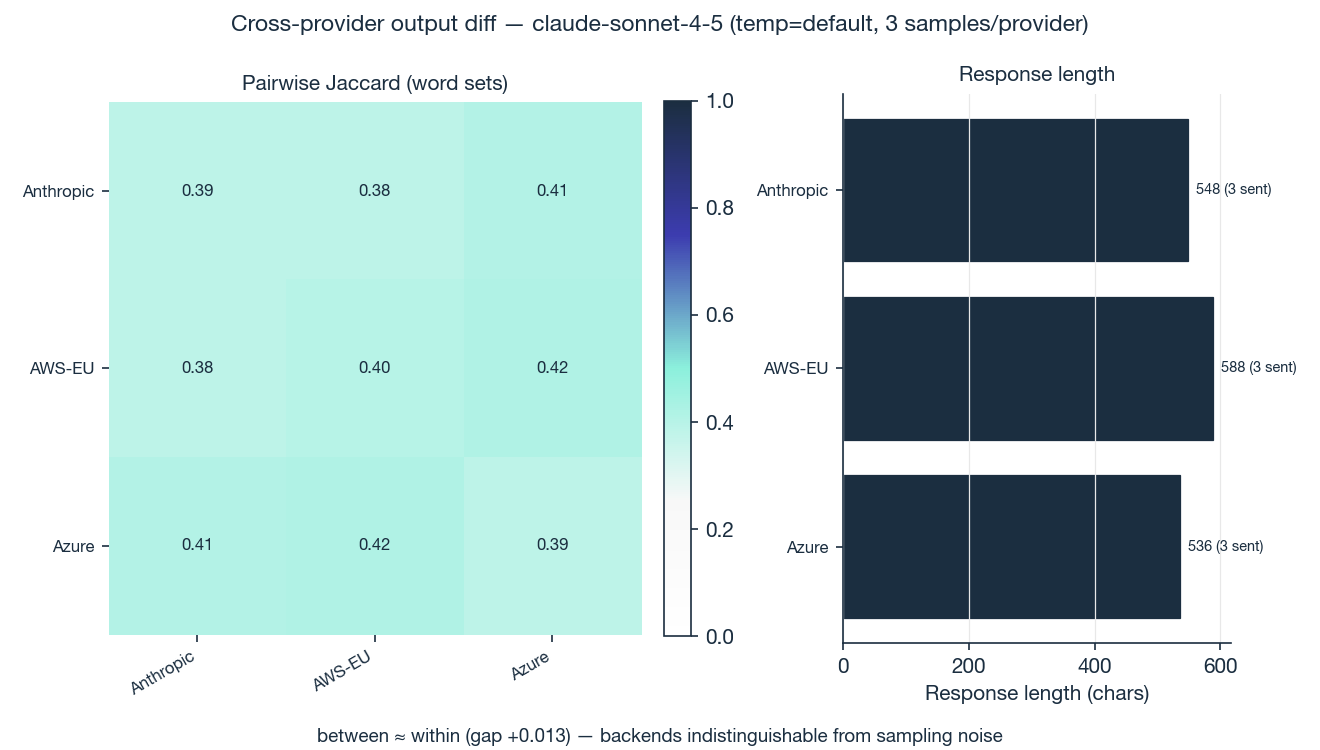
How similar are responses within the same backend (the baseline for "normal variation"): 0.476. How similar are responses across different backends: 0.478. The gap is +0.002, well within noise.
A backend agrees with another backend's output about as much as it agrees with its own next attempt. No evidence of different model versions, hidden system-prompt injection, different sampling defaults, or output drift between Anthropic direct and Azure deployments.
Three samples per backend is the minimum, and "no evidence of difference" is a weaker claim than "definitely the same." But for the resolution we tested at, the promise holds.
Takeaway: when Opper routes your call through whichever Claude deployment is cheapest at the moment, you're not silently being given a different product.
Takeaways
-
There is no blanket "router tax." Each router makes different tradeoffs. One was faster on first token than OpenAI direct; another matched it exactly. Test the specific router you're evaluating.
-
Region beats model tier. Geography is a bigger lever on user-perceptible latency than model tier is. If your users are in Europe, the change that matters is the region, not the tier.
-
Backend selection inside a router is a 10x lever. "I'm using
gpt-oss-120b" describes about 10% of what's happening to your users. Address backends explicitly when your provider lets you. -
Prompt caching is doing work on every backend. By turn 6 of a real conversation, most backends were running 20–40% faster than they would without caching. Only 3 of 10 actually report cache hits; the others cache silently.
-
"Same model" is the same model at the resolution we tested.
claude-sonnet-4-5served via Anthropic, AWS, and Azure is indistinguishable from itself.
The bigger lesson underneath: "which provider should I use?" no longer has a single answer. It has at least four, conditional on which model, which region, which workload, and which time of day. The only way to avoid getting burned is to measure the slice that matters for your specific app.
If you have a question about model or provider selection that you'd like us to actually run the test for, send it to us. We'd much rather measure it than speculate. If you want to follow what we're doing next, Opper is here.
Study scope and caveats
We designed these tests to answer real questions quickly. Here's what we didn't control for:
Sample sizes varied by test complexity. 200 calls for router comparison, 30 for backend testing, 3 for output consistency. Larger samples would give tighter confidence intervals.
No statistical significance testing. We compared confidence ranges directly rather than computing p-values. The patterns were clear enough for practical decisions, but formal stats would strengthen the claims.
Single vantage point. Regional tests ran from Sweden only. Results would vary from other geographic starting points.
No environmental controls. We didn't control for time of day, provider load, or network conditions. Real production traffic sees all of these variables.
Selected metrics. We focused on latency and throughput because that's what matters for our use cases. Your app might care more about cost, accuracy, or other factors we didn't measure.
The goal was practical guidance for deployment decisions. We'll expand the methodology in future iterations based on what questions this raises.