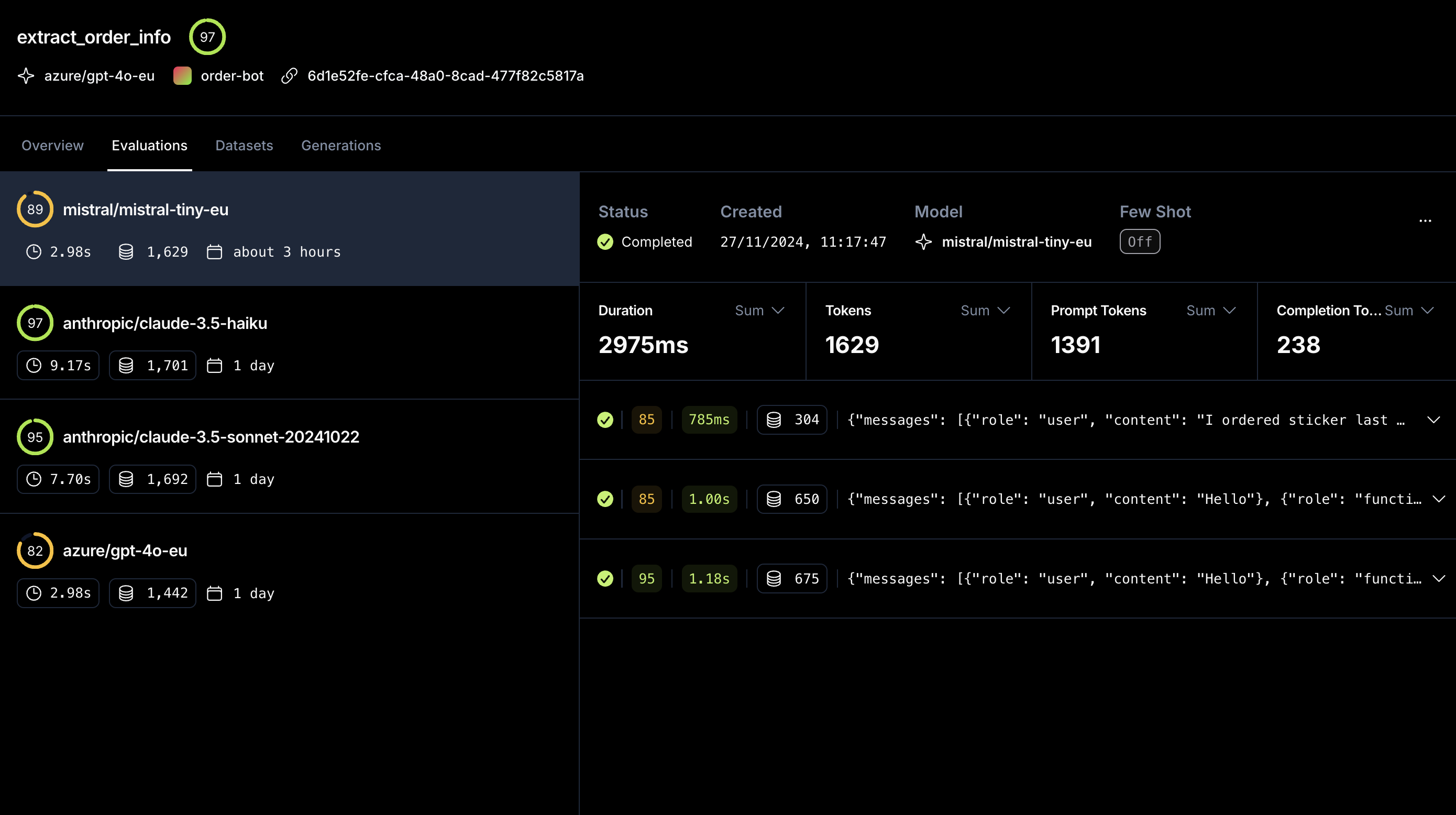
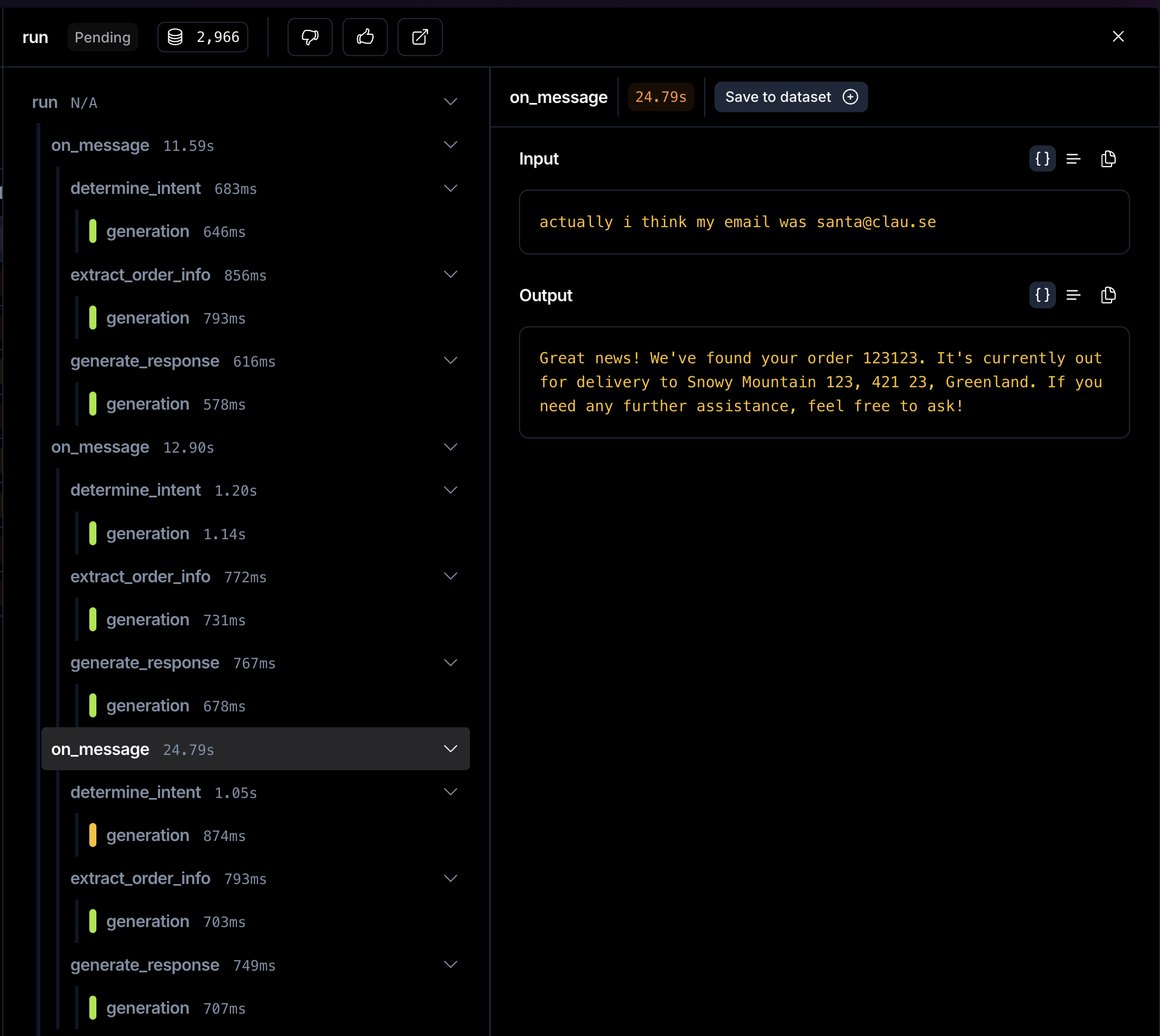
The opper:web_search server-side tool lets any model on Opper search the web, not just the labs that ship a native tool. One tool entry, identical response artifacts, every compat endpoint (Chat Completions, Anthropic Messages, OpenAI Responses, Gemini generateContent).
engine selection: auto (native when available, Opper otherwise), native, opper, or pin a backend with jina / exa
Jina (EU-hosted) and Exa (neural search) backends, with more on the way
Search can run fully in the EU via the Jina backend, so queries and fetched pages stay on European infrastructure
Per-search cost itemized in the response under usage.opper.cost.tools.web_search
Block-level citations on the Opper engine, anchored per-statement on the native route, read from the same place your endpoint already uses
Server-side searches now render as a dedicated server_side_tool step in the trace view, nested under the turn that requested it, showing the query, the results, and the cost. Works across every compat endpoint.
Opper Python SDK v0.4.0
This release introduces significant improvements to agent transparency and performance, focused on providing developers with better control over execution and costs.
Usage & Cost Tracking: The Agent.run() method now returns a detailed breakdown of token usage and costs for every agent run, including sub-agent and tool calls.
Parallel Tool Execution: Agents can now execute multiple tool and sub-agent calls concurrently using the new parallel_tool_execution parameter, significantly reducing latency for complex tasks.
Unified Agent API: Simplified development with a single Agent class, replacing and deprecating the previous ReactAgent and ChatAgent implementations.
Enhanced Tool Definitions: Support for output_schema and examples in tool definitions provides better guidance to LLMs and enables richer, typed outputs.
We've added support for OpenAI's gpt-5.2-codex model, optimized for coding tasks.
Input: $0.75/M tokens
Output: $4.00/M tokens
cerebras/glm-4.7
We've added support for the cerebras/glm-4.7 model from Cerebras.
Input: $2.25/M tokens
Output: $2.75/M tokens
fireworks/minimax-m2.1
We've added support for the Minimax M2P1 model, available via fireworks/minimax-m2.1.
Input: $0.30/M tokens
Output: $0.20/M tokens
Node Agents SDK v0.4.0
We have released version 0.4.0 of the Opper Node.js SDK with significant improvements to usage tracking, tool definitions, and event handling.
Usage Tracking with run()
The new run() method replaces process() as the primary way to interact with agents. It returns both the agent's result and detailed usage statistics, including token breakdowns for parent and nested agents or tools.
Tools now support outputSchema and examples, providing the LLM with better context for structured I/O and improving overall performance and reliability.
Unified Event System
The event and hook system is now fully unified. You can monitor all 17 event types (lifecycle, tool, memory, streaming) using the standard agent.on() API.
This release of the Opper Python Agent SDK introduces several improvements to developer experience and observability.
Configurable Tool Timeouts
You can now configure the maximum time an agent waits for a tool to respond using the agent_tool_timeout parameter. This defaults to 120 seconds and can be adjusted or disabled based on your needs.
Enhanced Trace Observability
Span tracking now includes visual hierarchy and emojis to make it easier to follow complex agent execution paths and identify different types of operations at a glance.
Improved Streaming
User messages and agent outputs are now displayed more clearly during streaming, providing better real-time feedback for long-running operations.
A new feedback API endpoint to capture quality signals from your production systems. Submit a score and optional free text on any call output, ideal for applications that already collect user signals like thumbs up/down or task success metrics.
Score + free text feedback to capture both quantitative and qualitative signals
Automatic example saving – high-quality outputs are automatically added to datasets for in-context learning
Pattern analysis – feedback signals help identify good and bad patterns over time
Dynamic few-shot learning by providing relevant examples at call time
No retraining required – improvements take effect immediately
Alerts on Quality Degradation
Proactively monitor your AI functions with automatic quality alerts. Opper now detects when your functions start to underperform and notifies you before issues impact users.
Enable them in the function overview , in the platform.
Automatic detection of quality regressions based task performance
Configurable thresholds to match your quality requirements
Email notifications to keep your team informed
Models
Added support for Grok 4.1, expanding the portfolio of high-performance models available via the Opper API.
xai/grok-4-1-fast-non-reasoning
xai/grok-4-1-fast-reasoning
Added support for the new Google Gemini 3 Flash Preview model:
gcp/gemini-3-flash-preview
Multi-Provider Alias for Claude Opus 4.5
Claude Opus 4.5 is now available across multiple cloud providers with automatic failover support via model aliases.
Use multi/claude-opus-4.5 to automatically route requests across all available Opus deployments with built-in failover:
azure/claude-opus-4.5
aws/claude-opus-4.5-eu
gcp/claude-opus-4.5
anthropic/claude-opus-4.5
If one provider is unavailable, requests seamlessly route to the next available option.
Models
Opper now supports EU-based inference for all major AI lab models.
Added a new provider: Novita.
Introduced DeepseekOCR, the top OCR benchmark scorer.
New Models:
novita/deepseek-ocr
novita/minimax-m2
gcp/gemini-2.5-pro-eu
gcp/gemini-2.5-flash-eu
gcp/gemini-2.5-flash-lite-eu
gcp/claude-sonnet-4
gcp/claude-sonnet-4-eu
gcp/claude-sonnet-4.5
gcp/claude-sonnet-4.5-eu
groq/gpt-oss-safeguard-20b
xai/grok-4-eu
xai/grok-4-fast-non-reasoning-eu
xai/grok-4-fast-reasoning-eu
xai/grok-code-fast-1-eu
Opper Agent SDKs
We've released new Opper Agent SDKs for Python & TypeScript – a powerful framework for building intelligent, headless agents that can reason, act, and collaborate seamlessly.
Key features include:
Simple 3-step agent creation with tools and model selection
Model Context Protocol (MCP) integration for external services
Model interoperability across all supported LLM providers
Comprehensive hook system for lifecycle management
Multi-agent systems with agent-to-agent delegation
Built-in observability and tracing
Production-ready with type safety, error handling, and async support
We've enhanced our streaming capabilities with structured streaming support, enabling real-time streaming of structured JSON data with precise field tracking.
Key Features
Two Streaming Modes:
Text Mode: Traditional incremental text streaming for conversational AI and open-ended responses
Structured Mode: Stream structured JSON with precise field tracking via json_path
JSON Path Tracking:
When using output_schema, each streaming chunk includes a json_path field showing exactly which schema field is being populated:
response.summary → Top-level string field
response.people[0].name → Name of first person in array
response.people[1].role → Role of second person
response.metadata.created_at → Nested object field
This enables precise UI updates where you can route streaming content to specific components based on the path, creating responsive real-time interfaces.
Example Usage:
from opperai import Opper
opper = Opper(http_bearer="YOUR_API_KEY")
# Stream a story with structured output schema
stream_response = opper.stream(
name="story_writer",
instructions="Write a short story about a robot discovering emotions",
input={"theme": "robot emotions", "length": "short"},
output_schema={
"type": "object",
"properties": {
"title": {"type": "string", "description": "Story title"},
"body": {"type": "string", "description": "Story content"},
"author": {"type": "string", "description": "Author name"}
}
},
model="openai/gpt-4o-mini"
)
for event in stream_response.result:
if hasattr(event, "data") and hasattr(event.data, "json_path"):
field = event.data.json_path
content = event.data.delta
if field == "response.title":
print(f"📖 Title: {content}", end="", flush=True)
elif field == "response.body":
print(f"{content}", end="", flush=True) # Stream story content
elif field == "response.author":
print(f"\n✍️ Author: {content}")
Create model aliases to improve reliability and simplify model management. Aliases are organization-scoped friendly names that map to an ordered list of fallback models.
Create an alias:
curl -X POST https://api.opper.ai/v2/models/aliases \
-H "Authorization: Bearer YOUR_OPPER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "sonnet4",
"fallback_models": ["aws/claude-sonnet-4-eu", "anthropic/claude-sonnet-4"],
"description": "Preferred Claude Sonnet with fallback"
}'
Use the alias:
opper.call(model="sonnet4", ...) # Automatic fallbacks included
Benefits:
Higher success rates: automatic failover when models are unavailable
Easier operations: no alerts when providers have issues
Safer upgrades: swap models without touching application code
Team consistency: shared aliases across your organization
Added Sonnet 3.7 model (AWS US region), aws/claude-3.7-sonnet, to the platform
Added fireworks/deepseek-v3-0324 model to the platform
Platform
Introduced a new pricing model with more granular service tracking, providing greater transparency and cost control for your AI operations
OpenAI GPT Image 1 Model: New Image Generation Capability
We've added OpenAI's new gpt-image-1 model to our platform, expanding our image generation capabilities. This addition gives you access to OpenAI's latest image generation technology:
openai/gpt-image-1
Embeddings Support in Node.js SDK
We've added embeddings functionality to the Node.js SDK, enabling you to generate vector embeddings for your text content. This new capability allows you to perform semantic search, content clustering, and other vector-based operations directly through our Node.js interface.
Evaluations Support in Python and Node.js SDKs
We've added support for creating evaluations directly from the Node.js SDK. This new capability allows you to create and manage evaluations programmatically.
Embeddings Support in Python SDK
We've added embeddings functionality to the Python SDK, enabling you to generate vector embeddings for your text content. This new capability allows you to perform semantic search, content clustering, and other vector-based operations directly through our Python interface.
Gemini 2.5 Flash Model
We've added Google's Gemini 2.5 Flash exp model to our platform:
gcp/gemini-2.5-flash
Claude 3.7 Sonnet on AWS
We've added the Claude 3.7 Sonnet model to our AWS provider:
aws/claude-3.7-sonnet-eu
OpenAI o3 and o4-mini models
Added openai/o3
Added openai/o4-mini
OpenAI GPT-4.1 Models: New AI Options
We've added OpenAI's latest GPT-4.1 models to our platform, giving you access to their newest and most capable AI models. These additions expand your options for powerful, state-of-the-art AI capabilities:
Added openai/gpt-4.1
Added openai/gpt-4.1-mini
Added openai/gpt-4.1-nano
New Grok 3 Models Avilable
Added xai/grok-3
Added xai/grok-3-mini-beta
Updated Mistral Models on Azure
We've replaced the retired Mistral model with the latest version available on Azure. This update ensures continued access to Mistral's powerful language capabilities with improved performance:
azure/mistral-large-eu is using the latest Mistral Large model (2411)
azure/mistral-large-2407-eu has been removed
PDF Media Type: Node.js SDK
We've added PDF media type support to the Node.js SDK (v2.7.0), enabling you to work with PDF documents in your applications. This enhancement expands the range of file types you can process using our SDK and simplifies PDF document handling in your Node.js projects.
Llama 4 Scout: New Model on Groq
We've added Meta's Llama 4 Scout model to our Groq integration, giving you access to this powerful new instruction-tuned model. Llama 4 Scout provides excellent performance while maintaining efficiency, expanding your options for AI-powered applications.
groq/llama-4-scout-17b-16e-instruct
Llama 4 Maverick: New Model on Groq
We've added Meta's Llama 4 Maverick model to our Groq integration, giving you access to this powerful new instruction-tuned model. Llama 4 Maverick features an impressive 131,072 token context window and 8,192 max completion tokens, allowing you to process much larger documents and conversations in a single request.
groq/llama-4-maverick-17b-128e-instruct
Gemini 2.5 Pro: Experimental Version
We have updated the Gemini 2.5 Pro model to an experimental version, providing our customers with access to the latest advancements in AI technology.
gcp/gemini-2.5-pro-exp-03-25
Cursor Rules: AI-Powered Code Assistance
We have released markdown files for AI code editors like Cursor that provide context for using the Opper SDK. These files serve as comprehensive guides for AI tools to understand how to interact with Opper for structured calls, indexing operations, tracing, and evaluations.
Available for both Python and TypeScript
Place in your project as .cursor/rules/opper.mdc
Enhances AI coding assistance with Opper-specific knowledge
In order to use the new Thinking mode in Claude 3.7, you can do something like this:
import asyncio
import os
from opperai import AsyncOpper
from opperai.types import CallConfiguration
opper = AsyncOpper()
async def main():
result, _ = await opper.call(
name="respond",
model="anthropic/claude-3.7-sonnet",
input="What is the capital of Sweden?",
configuration=CallConfiguration(
model_parameters={
"thinking": {
"type": "enabled",
"budget_tokens": 1024,
},
}
),
)
print(result)
asyncio.run(main())
Embeddings API
The API now supports getting embeddings for arbitrary input. While our indexes are the most straightforward way of using external knowledge for RAG use-cases and other things, this provide advanced users greater control over embeddings for custom use-cases.
We have added support for Gemini 2.0 Flash-Lite, hosted by Google Cloud Platform (US). You can access it in Opper using the model name:
gcp/gemini-2.0-flash-lite-preview-02-05
OpenAI API/SDKs Compatibility Layer
We have added an OpenAI compatibility layer that allows you to use Opper models with the OpenAI API and SDKs. This gives you the ability to use any model provided by Opper in any project that uses the OpenAI API/SDKs.
The compatibility layer supports additional Opper functionality through extra body arguments:
fallback_models: A list of models to use if the primary model is not available
tags: A dictionary of tags to add to the request
span_uuid: The UUID of the span to add to the request
evaluate: Whether to evaluate the generation or not
Python example using these features:
import os
from openai import OpenAI
from opperai import Opper
opper = Opper()
client = OpenAI(
base_url="https://api.opper.ai/compat/openai",
api_key="-", # must not be blank
default_headers={"x-opper-api-key": os.getenv("OPPER_API_KEY")},
)
with opper.spans.start("reverse-name") as span:
response = client.chat.completions.create(
model="gorq/deepseek-r1-distill-llama-70", # This model is not available since provider is called "gorq" and not "groq"
messages=[
{"role": "user", "content": "What is the capital of France? Please reverse the name before answering."}
],
extra_body={
"fallback_models": [
"groq/deepseek-r1-distill-llama-70b",
],
"tags": {
"user_id": "123",
},
"span_uuid": str(span.uuid),
"evaluate": False,
}
)
Node example using these features:
import { OpenAI } from "openai";
import OpperAI from "opperai";
const opper = new OpperAI();
const client = new OpenAI({
baseURL: "https://api.opper.ai/compat/openai",
apiKey: "OPPER_API_KEY",
defaultHeaders: { "x-opper-api-key": "OPPER_API_KEY" },
});
async function main() {
const trace = await opper.traces.start({
name: "node-sdk/using-the-openai-sdk",
input: "What is the capital of France? Please reverse the name before answering.",
});
const completion = await client.chat.completions.create({
model: "openai/gpt-4o-mini",
messages: [
{
role: "user",
content: "What is the capital of France? Please reverse the name before answering.",
},
],
// @ts-expect-error These are Opper specific params.
// fallback_models: ["openai/gpt-4o-mini"],
span_uuid: trace.uuid.toString(),
// evaluate: false,
});
await trace.end({ output: { foo: completion.choices[0].message.content } });
}
main();
Gemini 2.0: Flash
We have added support for Gemini 2.0 Flash, hosted by Google Cloud Platform (US). You can access it in Opper using the model name:
gcp/gemini-2.0-flash
Billing enabled
You can now add your credit card in the Opper platform to enjoy unlimited usage. The free tier continues to exist, but has a limited usage allowance per month for experimentation and testing.
Gemini 2.0 Flash Thinking
The new experiment from Google called Gemini 2.0 Flash Thinking is now available to test in Opper.
gcp/gemini-2.0-flash-thinking-exp
Deepseek R1
We have added support for Deepseek R1. You can access it in Opper using this model name:
fireworks/deepseek-r1
Deepseek v3
We have added support for Deepseek v3, hosted by Fireworks AI (US). You can access it in Opper using this model name:
fireworks/deepseek-v3
New models
We have added support for the following new models.
gcp/gemini-2.0-flash-exp
groq/llama-3.3-70b-versatile
OpperCLI now supports showing usage information
The OpperCLI now supports showing usage information for your account. This can be used to get an overview of your usage, and optionally grouped by your custom call tags.
The basic usage showing total_tokens looks like this:
➜ opper usage list --fields=total_tokens
Usage Events:
Time Bucket: 2024-12-03T00:00:00Z
Cost: 0.029731
Count: 25
total_tokens: 4806
Time Bucket: 2024-12-04T00:00:00Z
Cost: 0.025908
Count: 13
total_tokens: 4155
Time Bucket: 2024-12-06T00:00:00Z
Cost: 0.017290
Count: 7
total_tokens: 2689
More usage information can be found by running the command:
➜ opper usage
Manage usage information
Usage:
opper usage [command]
Examples:
# List usage information
opper usage list
# List usage with time range and granularity
opper usage list --from-date=2024-01-01T00:00:00Z --to-date=2024-12-31T23:59:59Z --granularity=day
# List usage with specific fields and grouping
opper usage list --fields=completion_tokens,total_tokens --group-by=model,project.name
# Show count over time as ASCII graph (default)
opper usage list --graph
# Show cost over time as ASCII graph
opper usage list --graph=cost
# Show count over time by model
opper usage list --group-by model --graph
# Export usage as CSV
opper usage list --out csv
Tracking calls using a customer tag looks like this. First include the customer tag in the call:
Then run the opper usage list --group-by=customer command to see the usage information grouped by the customer tag.
➜ opper usage list --fields=total_tokens --group-by=customer
Usage Events:
Time Bucket: 2024-12-06T00:00:00Z
Cost: 0.025908
Count: 13
customer: <nil>
total_tokens: 4155
Time Bucket: 2024-12-06T00:00:00Z
Cost: 0.000007
Count: 1
customer: mycustomer
total_tokens: 23
New feature: Run evaluations on alternative models and prompts
Opper now supports running ad hoc evaluations with different models, instructions and function configurations. It works by running through a functions dataset entries and evaluating the results. This allows for testing how a function performs with current or alternative configuration.
See our documentation on Offline Evals for more information.
Updates to managing datasets
We have improved handling of datasets to help make it easier to populate them:
Dataset entries now includes an expected field that is used in evaluations and in few shot configuration.
Dataset entries can be populated from any trace, by uploading a json file or through the sdks.
We added an llms.txt file to https://opper.ai to assist AI code editors like Cursor to find relevant documentation about Opper. See https://llmstxt.org/ for more information.
New models
We have added support for the following new models:
gcp/gemini-exp-1114
gcp/gemini-exp-1121
mistral/pixtral-large-latest-eu
xai/grok-beta
xai/grok-vision-beta
Support for custom models
There is now support for custom models in Opper. This means that you can bring your own key to an existing model or add a completely custom model.
The easiest way to add a model is to use the Opper CLI. The README explains how to add a model, but here is an example of adding your own Azure deployment:
This adds your custom deployment on my-gpt4-deployment.openai.azure.com and the model name gpt4-production using the my-api-key-here API key. This model is then accessible in Opper using the name example/my-gpt4.
Support for fallback models
The Opper API now support providing a list of fallback models, in addition to the main model used in a call. They will be tried in order until a model returns successfully.
Python sync example
from opperai import Opper
opper = Opper()
response, _ = opper.call(
name="GetFirstWeekday",
input="Today is Tuesday, yesterday was Monday",
instructions="Extract the first weekday mentioned in the text",
model="azure/gpt-4o-eu",
fallback_models=["openai/gpt-4o"],
)
print(response)
Python async example
from opperai import AsyncOpper
import asyncio
opper = AsyncOpper()
async def main():
response, _ = await opper.call(
name="GetFirstWeekday",
input="Today is Tuesday, yesterday was Monday",
instructions="Extract the first weekday mentioned in the text",
model="azure/gpt-4o-eu",
fallback_models=["openai/gpt-4o"],
)
print(response)
if __name__ == "__main__":
asyncio.run(main())
Node example
import OpperAI from 'opperai';
import fs from "fs";
import path from "path";
import os from "os";
async function testCallFallback() {
// Replace 'your-api-key' with your actual OpperAI API key
const client = new OpperAI({ apiKey: 'your-api-key' });
const { message, span_id } = await client.call({
name: "GetFirstWeekday",
input: "Today is Tuesday, yesterday was Monday",
instructions: "Extract the first weekday mentioned in the text",
model: "azure/gpt-4o-eu",
fallback_models: ["openai/gpt-4o"],
});
console.log(message);
}
testCallFallback();
Added support for Anthropic Claude 3.5 Haiku
import asyncio
from opperai import AsyncOpper
async def haiku():
aopper = AsyncOpper()
res, _ = await aopper.call(
model="anthropic/claude-3.5-haiku",
name="new-haiku-3-5",
instructions="answer the following question",
input="what are some uses of 42",
)
print(res)
asyncio.run(haiku())
Enhanced Sidebar for Project Navigation
With our new sidebar update, users can now effortlessly select their desired projects directly from the side panel. This improved navigation persists across indexes, traces, and functions, ensuring a seamless workflow experience.
Added Metrics Filtering
We've upgraded our metrics display within trace spans. Users can now apply filters to better manage the metrics they need to focus on. These enhancements provide a clearer, more accessible presentation of data within the trace table.
Streaming support for call()
It is now possible to stream the response from the call() method.
import asyncio
from opperai import AsyncOpper
async def stream():
aopper = AsyncOpper()
res = await aopper.call(
model="anthropic/claude-3.5-sonnet",
input="what are some uses of 42",
stream=True,
)
async for chunk in res.deltas:
print(chunk)
asyncio.run(stream())
Added support for updated version of Anthropic Claude 3.5 Sonnet
import asyncio
from opperai import AsyncOpper
async def sonnet():
aopper = AsyncOpper()
res, _ = await aopper.call(
model="anthropic/claude-3.5-sonnet-20241022",
name="new-sonnet-3-5",
instructions="answer the following question",
input="what are some uses of 42",
)
print(res)
asyncio.run(sonnet())
The anthropic/claude-3.5-sonnet model now defaults to the updated version.
Updated default model
If you do not explicitly provide a model in your call(), it will now default to the azure/gpt-4o-eu model.
Added support for Imagen 3 in the Python and Node SDKs
Opper now support two image generation models, azure/dall-e-3-eu and gcp/imagen-3.0-generate-001-eu. Here is an example of generating an image from a description in Python:
def generate_image(description: str) -> ImageOutput:
image, _ = opper.call(
name="generate_image",
output_type=ImageOutput,
input=description,
model="gcp/imagen-3.0-generate-001-eu",
configuration=CallConfiguration(
model_parameters={
"aspectRatio": "9:16",
}
),
)
return image
description = "portrait of a person standing in front of a park. vibrant, autumn colors"
path = save_file(generate_image(description).bytes)
print(path)
Here is a similar example in TypeScript:
async function testImageGeneration() {
const image = await client.generateImage({
model: "gcp/imagen-3.0-generate-001-eu",
prompt: "portrait of a person standing in front of a park. vibrant, autumn colors",
configuration: {
model_parameters: {
aspectRatio: "9:16",
}
}
});
const tempFilePath = path.join(os.tmpdir(), "image.png");
fs.writeFileSync(tempFilePath, image.bytes);
console.log(`image written to temporary file: ${tempFilePath}`);
}
testImageGeneration();
Model parameters vary between models, but here are the supported ones for each model:
azure/dall-e-3-eu:
style: natural, vivid
quality: standard, hd
size: 1024x1024, 1792x1024, 1024x1792
gcp/imagen-3.0-generate-001-eu:
aspectRatio: 1:1, 3:4, 4:3, 16:9, 9:16
Images as input to multimodal models
You are now able to pass images as input to multimodal models.
Python SDK
# special type for images, this is to capture the need for encoding the image in the right format
from opperai import ImageInput
description, response = await aopper.call(
name="async_describe_image",
instructions="Create a short description of the image",
output_type=Description,
input=Image(
image=ImageInput.from_path("examples/cat.png"),
),
model="openai/gpt-4o",
)
Node SDK
// special function to read images, this is to capture the need for encoding the image in the right format
import { opperImage } from "opperai";
const { message } = await client.call({
parent_span_uuid: trace.uuid,
name: "node-sdk/call/multimodal/image-input",
instructions: "Create a short description of the image",
input: {image: image("examples/cat.png")},
model: "openai/gpt-4o",
});
Image generation using DALL-E 3 now available
Using the ImageOutput type you are now able to generate images via call using DALL-E 3 in the Python SDK.
from opperai import ImageOutput
cat, _ = await aopper.call(
name="generate_cat",
output_type=ImageOutput,
input="Create an image of a cat",
)
Using the Node SDK you can generate images using DALL-E 3.
const cat = await client.generateImage({
parent_span_uuid: trace.uuid,
prompt: "Create an image of a cat",
});
New models added
aws/claude-3.5-sonnet-eu
cerebras/llama3.1-8b
cerebras/llama3.1-70b
gcp/gemini-1.5-pro-002-eu
gcp/gemini-1.5-flash-002-eu
groq/llama-3.1-70b-versatile
groq/llama-3.1-8b-instant
groq/gemma2-9b-it
mistral/pixtral-12b-2409-eu
openai/o1-preview
openai/o1-mini
See Cerebras for more information about these models.
Updated default embedding model
The new default embedding model for indexes is text-embedding-3-large.
New models added
azure/meta-llama-3.1-405b
azure/meta-llama-3.1-70b-eu
azure/mistral-large-2407
mistral/mistral-large-2407
openai/gpt-4o-2024-05-13 (openai/gpt-4o currently points to this)
openai/gpt-4o-2024-08-06
Add examples at call time
You can now add examples at call time. This is useful if you have a set of examples that you want to use as a reference for your model without having to manage a dataset.
output, _ = opper.call(
name="changelog/python/call-with-examples",
instructions="extract the weekday from a text",
examples=[
Example(input="Today is Monday", output="Monday"),
Example(input="Friday is the best day of the week", output="Friday"),
Example(
input="Saturday is the second best day of the week", output="Saturday"
),
],
input="Wonder what day it is on Sunday",
)
The three ways of tracing your code using the Python SDK
Manually
span = opper.traces.start_trace(name="my_function", input="Hello, world!")
# business logic here
span.end()
Using context manager
with opper.traces.start(name="my_function", input="Hello, world!") as span:
# business logic here
Using the @trace decorator
@trace
def my_function(input: str) -> str:
# business logic here
Call a LLM without explicitly creating a function using the Python SDK
You can now call a LLM without explicitly creating a function.
// Start parent trace
const trace = await client.traces.start({
name: "node-sdk/tracing-manual",
input: "Trace initialization",
});
// You can optionally start a child span and provide the input
const span = await trace.startSpan({
name: "node-sdk/tracing-manual/span",
input: "Some input given to the span",
});
// A metric and/or comment can be saved to the span
// A span generation can also be saved using .saveGeneration()
await span.saveMetric({
dimension: "accuracy",
score: 1,
comment: "This is a comment",
});
// End the span and provide the output
await span.end({
output: JSON.stringify({ foo: "bar" }),
});
// End the parent trace
await trace.end({ output: JSON.stringify({ foo: "bar" }) });
Call a LLM without explicitly creating a function using the Node SDK
You can now call a LLM without explicitly creating a function.
const { message } = await client.call({
name: "node-sdk/call/basic",
input: "what is the capital of sweden",
});
Manually adding generations
You can now manually add generations to your traces. This is useful if you call an LLM outside of Opper but still want to use the tracing capabilities of Opper.
We have added support for the just released GPT-4o mini model from OpenAI.
Projects now available
Projects allow you to create separation in Opper. Currently, the following is tied to a project:
Functions
Indexes
Traces
API keys
When you create an API for a specific project, all usage will be associated with that specific project automatically, so there is no need to pass the project as you are using it.
Manage organizations and invite your colleagues
You are now able to create your own organizations in Opper. Go to Settings --> Organization and click Create Organization in the top right corner to get started.
Once you have created your organization, you are able to invite your colleagues by sending an invite to their email address. Once they are in, you are able to collaborate and have a common view of your AI usage.