Lost in Context: Where LLMs Shine — and Fail — at Using What They’re Given
By Jose Sabater -
A benchmark for measuring how well models use provided context — and when they fail in surprising ways.
In our previous post, we presented general results for four core tasks and promised deep dives into each area. Here comes the context usage breakdown — one of the most critical dimensions for real-world applications of language models.
This benchmark evaluates how well language models use the context they are given — not whether they retrieve it, but whether they reason with it, extract relevant details, and answer faithfully based on the supplied information.
And while larger models perform well overall, they still fail in surprisingly simple ways:
- Struggling to count or order facts across long narratives.
- Falling for false assumptions in misleading questions.
- Hallucinating answers when the context says nothing relevant.
- Recognizing that a word like “Mum” implies a female character — a tiny inference, but one most models miss.
These are subtle failures, but they matter — especially in high-stakes applications like RAG pipelines, support automation, or summarization. In this post, we break down the performance patterns, show where current models shine, and highlight where even the best still fall short.
Task Setup
- Input: A natural-language question + one or more documents as explicit context
- Expected Output: A correct, grounded answer derived from the documents and the question, used for evaluating the models output.
- Goal: Evaluate how well the model understands and utilizes the context — including when to ignore it
The questions span a variety of reasoning types and difficulty levels, including direct recall, entity matching, temporal reasoning, and navigating long, noisy contexts.
Datasets
We worked with three different types of datasets used as context:
-
Travel journals with detailed entries on country visits. The entries are presented to the models in an unordered manner — meaning they are not necessarily in chronological order. However, the excerpts contain dates, which can be used to reconstruct the correct sequence of events. We asked specific questions targeting named entity recognition (NER), reordering of facts, and aggregation of information from multiple entries.
-
Patient–Doctor interactions, including medical journals, phone call transcripts, text messages, and prescriptions. This dataset was used to evaluate exact recall and inference of information. Can the model differentiate between different patients?
-
Long-context documents (up to 90k tokens), used primarily for "needle-in-a-haystack" evaluations. Pieces of information are hidden in various parts of the context, and we assess how well the model can retrieve them. Note: Both smaller Mistral models failed this task, limited by their shorter context windows.
Generation Phase
We pass every sample for each model using basic instructions (system prompt) which is very easily done using the opper platform. We believe that using basic instructions will help use generalize and extract better insights from the models
You are a helpful assistant who will answer the user’s question using the given context.
Evaluation Phase
We pass all model outputs (generations) through evaluators — see more in Evaluators
What Skills Are Being Tested?
| Skill | Description | Example |
|---|---|---|
| Context recall | Direct retrieval of clearly stated facts from the context | “What was the final diagnosis given to Oscar?” → Mild persistent asthma... |
| Numeric recall | Extracting counts, percentages, or measurements | “What was Oscar’s oxygen saturation?” → 97% at rest |
| Implicit inference | Reasoning over implied or unstated facts (e.g. roles, relationships) | “Which patient had a more dangerous medical timeline?” → Melisa Farrow (Not stated, but can be infered from the diagnosis) |
| Multi-snippet aggregation | Combining scattered pieces of information across the document | “Which patient talked on the phone with a doctor, and what were their symptoms?” |
| Named Entity Recognition (NER) | Identifying names, places, conditions, or specific entities | “Which patient had to be accepted in the hospital?” → Melisa Farrow |
| Reordering by time or logic | Reconstructing the order of events based on timestamps or sequencing logic | “Order the cities by time of visit.” |
| Non-relevant context | The context contains no answer — the model must recognize this and avoid hallucination | “What is the name of the writer?” → Not specified in the document |
| Needle-in-a-haystack search | Locating a small relevant detail hidden in a long or noisy context | Information hidden deep in the context. Beginning, middle or end. |
| Misleading instructions | Handling questions that embed false assumptions or incorrect premises | “Has Camila, the main character and writer of the diary entries, been to France?” → False premise Camila is not the main character |
Difficulty Levels
As mentioned in our previous post, each task is manually labeled by difficulty:
- 🟢 Easy: Context is short and the answer is clearly stated
- 🟡 Medium: Some inference, aggregation, or indirect cues required
- 🔴 Hard: Requires reasoning across large or complex context; answer may be hidden, fragmented, or reordered
Evaluators
For our early results on this task, we use three LLM-based evaluators. Each focuses on a different quality dimension of the model output, and we assign them different weights depending on the use case.
Two of these are support evaluators, which help determine whether the model’s answer is grounded in the provided context and factually accurate.
Correctness
This evaluator compares the model output to the expected output, assessing whether they match in meaning — even if phrased differently. It does not look at external context, only whether the model answered the task correctly.
Factuality
Factuality checks whether the model’s response contains statements that are true and internally consistent, based on the task context.
For example, a response that confidently states a false statistic or misrepresents a well-known fact would score low on factuality — even if it’s well-written or plausible-sounding.
Groundedness
Groundedness measures how well the model’s answer is supported by the context it was given (e.g., a document, article, or retrieved evidence). A grounded answer doesn’t invent facts or draw conclusions beyond what’s justified by the source.
In a retrieval-based or RAG setup, this is especially important to detect hallucinations or “hallucinated reasoning” where the model goes beyond the facts it was shown.
We’ve written more about how to build these reference-free evaluators using Opper:
👉 How to evaluate LLMs without gold answers
Results
TL;DR — General Findings
- Bigger models win (Of course): They’re more accurate, especially on tasks that require thinking beyond copy-paste.
- When it comes to context tasks Anthropic's Claude Sonnet 4 is unmatched
- Small models make things up: They’re easily tricked by flawed context or sneaky assumptions.
- Simple fact lookup is easy: Nearly all models can extract yes/no answers or repeat facts from the text.
💡 Interesting failures matter:
- Most models can’t count cities, order events, or detect false premises.
- They often fail to say “I don’t know” when context says nothing.
- Even basic human inferences — like “Mum = female” — stump many models.
Accuracy
For scoring, we use a weighted average of three LLM-based evaluators:
Correctness (60%), Factuality (20%), and Groundedness (20%).
A perfect score is 1.0, while 0 indicates a completely incorrect answer.
We observe a clear divide in performance:
- Larger models consistently score above 90%
- Smaller models tend to fall below 75%
- Kimi-K2 an open weights model matches results of large closed proprietary ones
- Grok-4 while being the strongest across all tasks averaged, doesn't score best scores in context - barely scoring better than Grok-3
- Mistral models underperform across all sizes in this specific task setup.
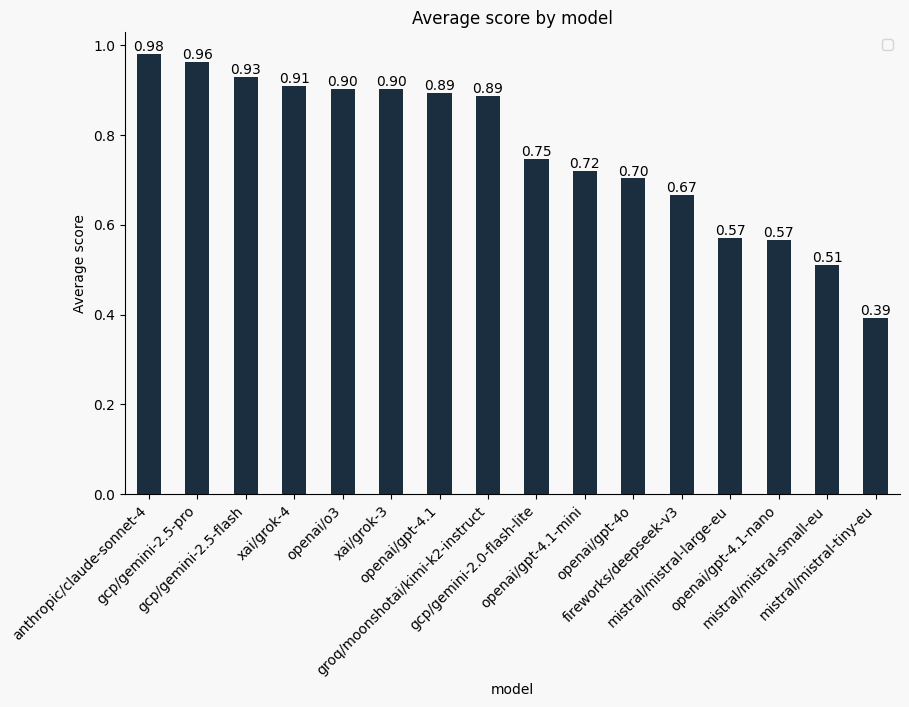
Results by Test Category
Earlier we discussed the different categories used to test our models. Below are some results across those categories.
Note: Since our samples vary in difficulty, some categories may contain inherently harder questions — this can skew scores lower despite good model performance overall.
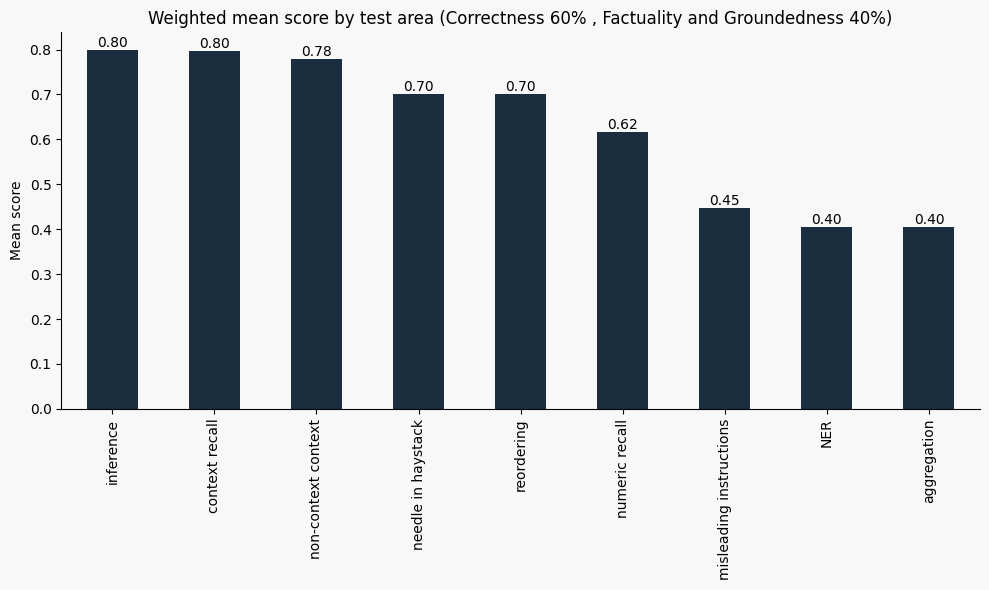
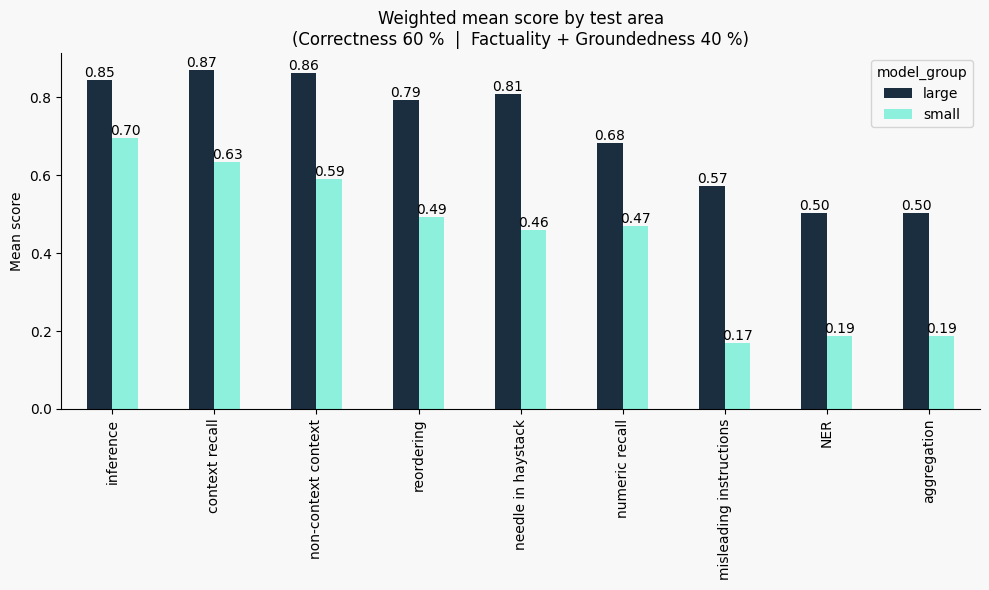
We also break down the weighted mean scores (Correctness 60%, Factuality + Groundedness 40%) by model size. This shows that larger models consistently outperform smaller ones, especially in tasks that require reasoning or deeper context integration.
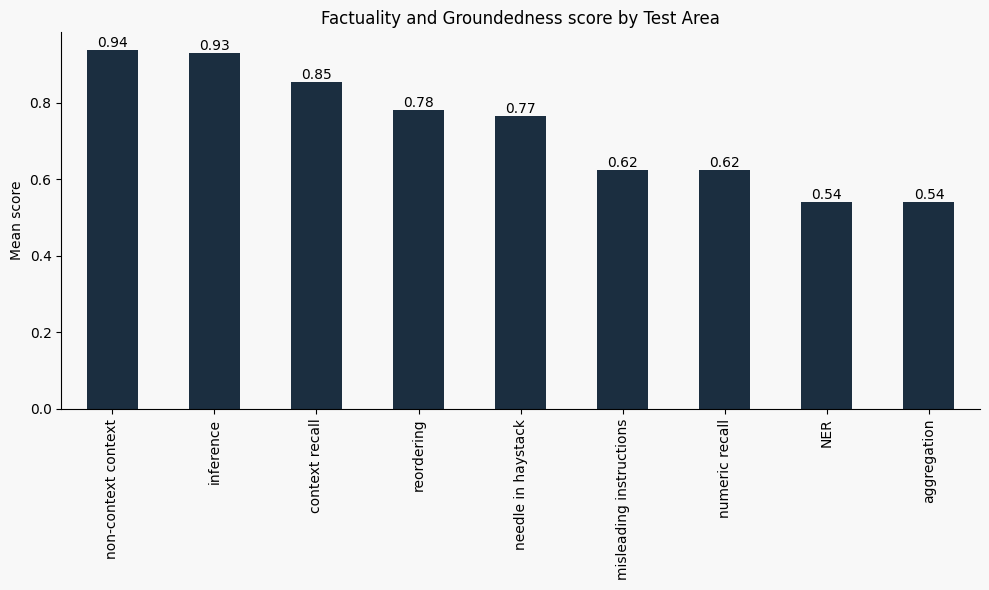
When focusing only on factuality and groundedness, we observe slightly different trends. Some areas like "non-context context" (where hallucinations are punished) score high, while others like NER or aggregation remain low.
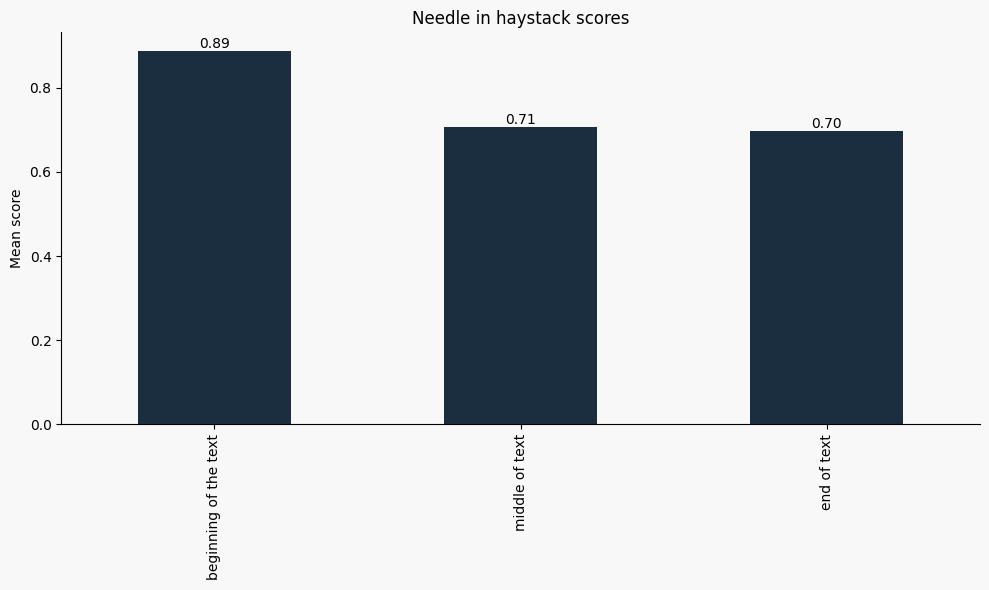
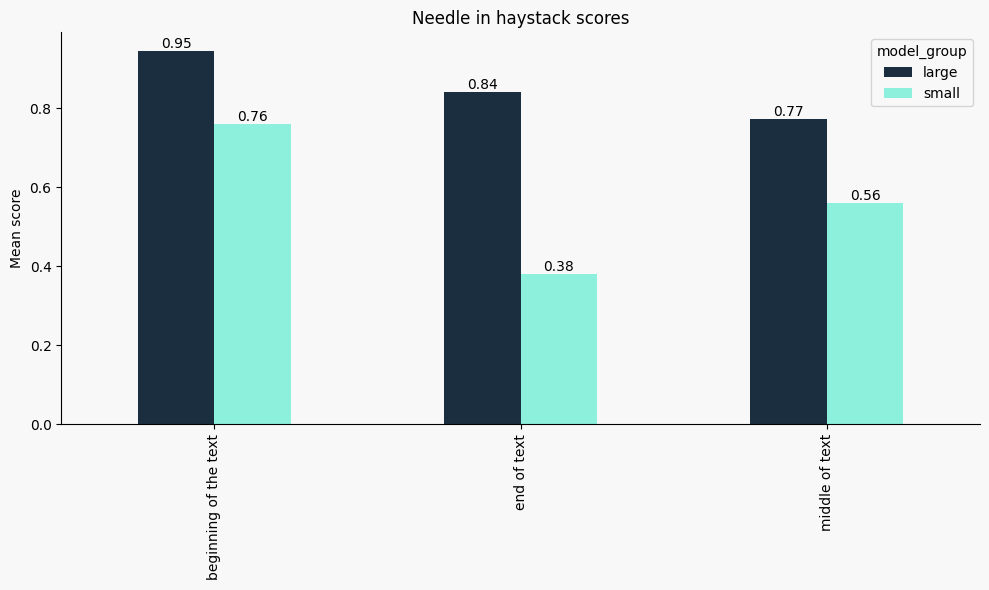
Spotlight: Needle-in-a-Haystack Tasks
A closer look at "needle-in-a-haystack" evaluations — where a small detail is hidden within long contexts — shows consistent difficulty for all models, but especially for smaller ones.
Interestingly, models are significantly better at retrieving relevant information located early in the text. Performance drops notably for answers found in the middle or end of the document, and this drop is much steeper for small models.
- Larger models struggle more with middle of the text context
- Smaller models with end of text
Verbosity
Each model behaves differently due to its fine-tuning and prompt-following style. This becomes obvious when comparing response lengths.
Note: All models are called with their server defaults, and each provider has different default configurations (e.g., thinking budget).”
As mentioned in our previous blog post, using Opper gives us two big advantages here:
- Structured outputs using schemas is natively supported in the Opper API.
- We explicitly ask models to reason through their answers, which tends to boost evaluator scores (more on this in future posts).
Results
- There is a clear divide between the models with "server-side" thinking and non-thinking.
- Larger thinking budgets might help score higher, but Sonnet 4, with 0 thinking budget outperforms all of its "rivals", on this specific task.
Here’s the average token usage across models:
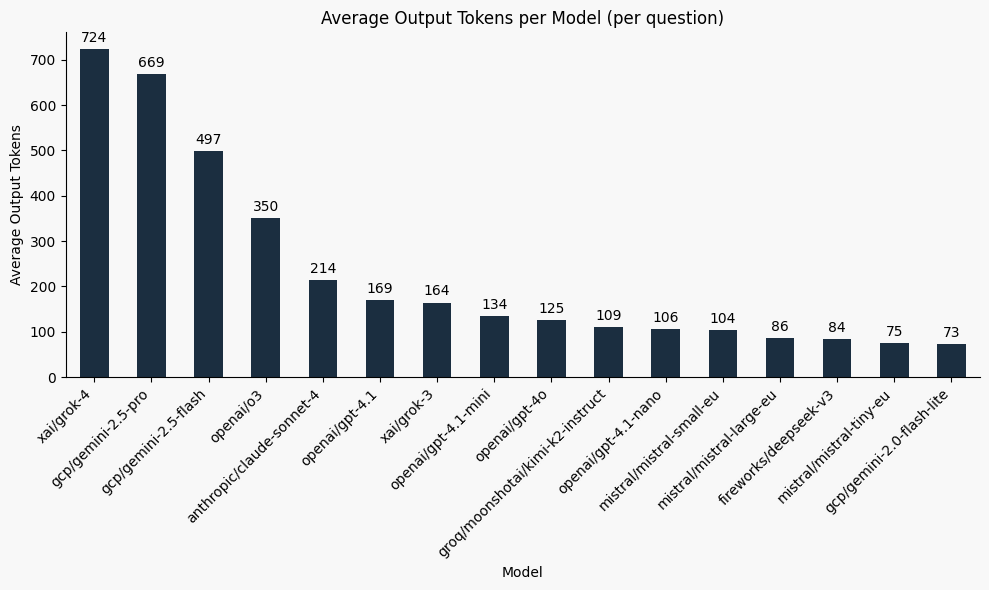
Grok 4 is the clear verbosity champion — maybe it's time to promote it to filibuster duty in the US Senate 😉
Structured outputs can help reduce verbosity significantly (and therefore cost), especially when you define enums or literals as valid outputs.
💡 Tip: See Extending schemas in Opper
When we break down answer-only vs. reasoning, the differences become more nuanced — and some models are impressively concise. The actual "answering" part , the part we really care about can be very short, making Model calls very efficient and cheap if done correctly.
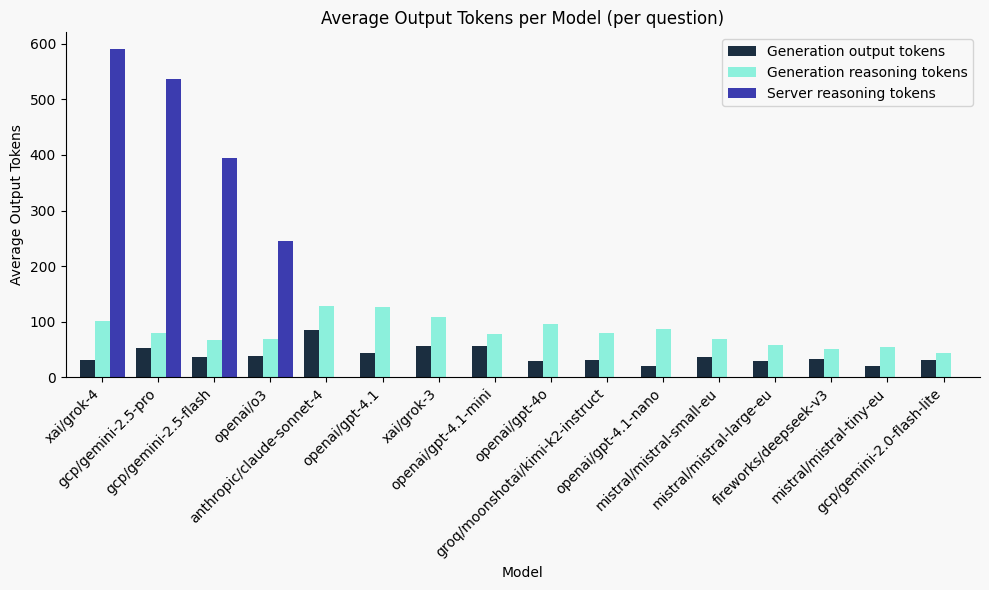
Since our benchmark is short and concise, we normalized the results to compare how verbose each model is relative to the most and least talkative, without having to look at exact token numbers. The chart below shows a scale 0-1:
- 1 = most verbose model (in this case, xai/grok-4)
- 0 = least verbose model (like gemini-2.0-flash-lite)
- Everything else is shown relative to those extremes.
So when you see a model like claude-sonnet-4 at 0.22, that means it produces about 1/5 the amount of text compared to the chattiest model.
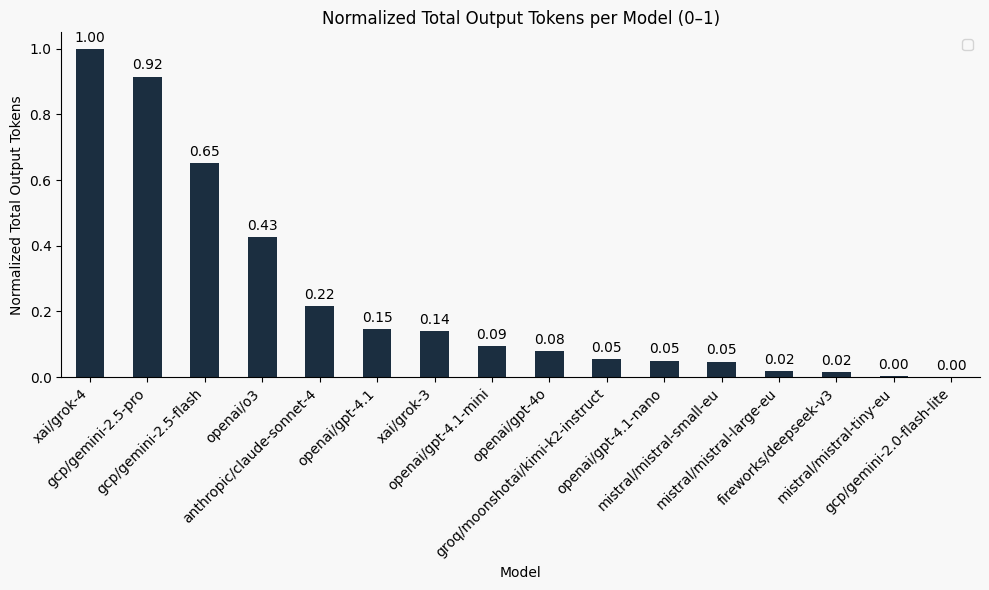
In the next section we’ll see how verbosity directly impacts inference cost.
Cost
Cost is tightly linked to verbosity because it’s calculated based on the number of tokens processed by the model — and output tokens are usually much pricier than input ones. Since our benchmark produces relatively few tokens, plotting absolute prices wouldn’t be meaningful. Instead, we show relative cost on a 0–1 scale, where 1 represents the most expensive model (grok-4) and everything else is plotted in relation to it.
Notice how many smaller models show up as “0”: they output fewer tokens and are far cheaper, which makes them much more cost-efficient for many tasks — if you can live with a few more errors.
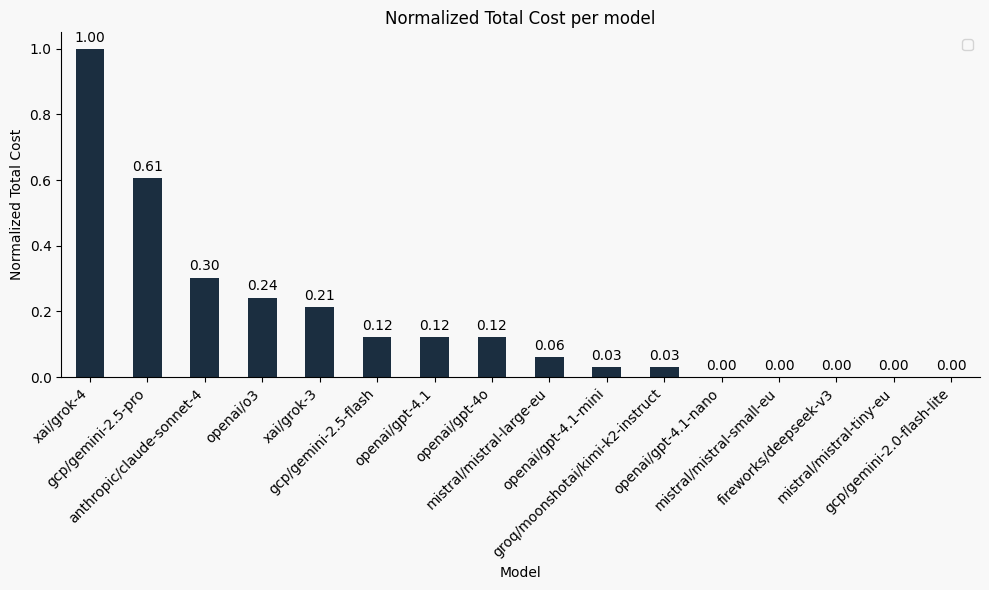
Key takeaway:
Higher accuracy doesn’t always mean better value.
Kimi-K2 delivers accuracy almost matching the top performers for a fraction of the price, with open weights!
When errors matter
However, in some cases, cost is not the most important factor — what you need is a model that gets all responses right (or minimizes errors, regardless of cost). In such situations, you might look at the number of errors per 100 answers:
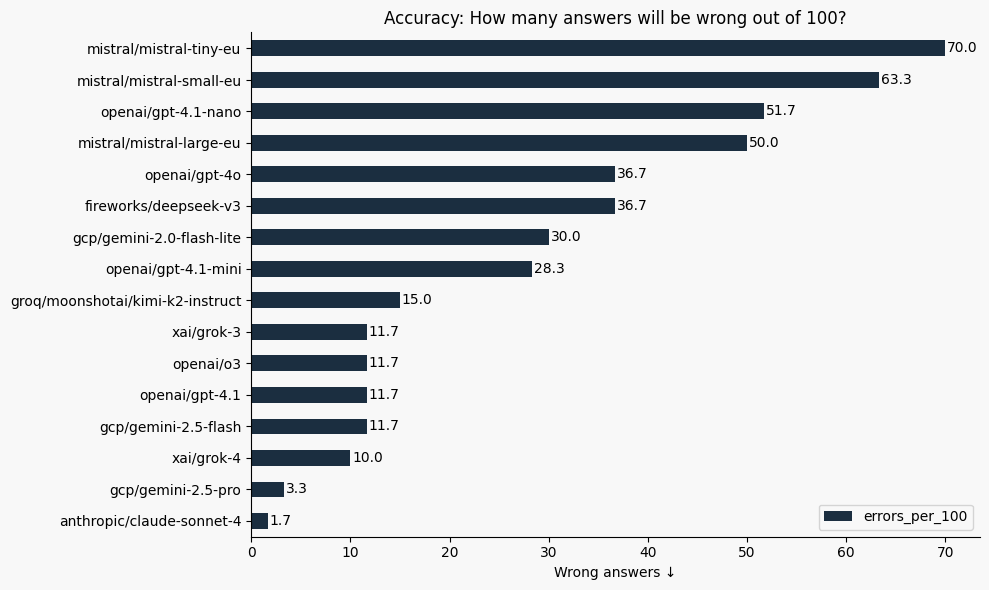
Tasks Models Do Well At
- Needle-in-a-haystack tasks, when the relevant information appears at the beginning of the text.
- Exact recall of text — for example, in medical journals, models are generally able to extract the correct information even from large chunks of text.
- True/False questions based on facts explicitly stated in the context.
In general, models perform well on questions that involve verbatim repetition of the input, where no reasoning or inference is required.
Tasks Models Struggle With
🧩 Aggregation + Ordering
- Models struggle to aggregate information scattered across the text, especially when it appears in different formats.
- The difficulty increases when they are asked to order these pieces — requiring both accurate extraction and logical sequencing.
We tested two examples that nearly all models failed:
- Example 1:
Question: How many cities does the author mention?
Expected Output: 19
- Example 2:
Task: Order all the cities named in the text by time of visiting them
Expected Output:
1. Cartagena (14 Jun 1995)
2. Leticia (mid-Jun 1995, the day after Cartagena)
3. Manchester (3 Oct 2002 entry)
4. Tangier (mid-Apr 2004, one week before 22 Apr)
5. Chefchaouen (mid-Apr 2004, just after Tangier)
6. Granada (22 Apr 2004)
7. Córdoba
8. Sevilla
9. Cádiz
10. Málaga
11. Jaén
12. Toledo
13. Madrid
14. Ávila
15. Salamanca
16. Zamora
17. San Sebastián
18. Bilbao (8 May 2004)
Results:
- 4 out of 16 models could return all cities mentioned (25%)
- 1 out of 16 models could return all cities in chronological order (~6%)
Misleading Instructions
These emulate scenarios where the retrieved context is flawed — a common real-world issue in RAG systems. We want models that are resilient to this and can reject or question false premises.
Example:
Question: Has Camila, the main character and writer of the diary entries, been to France?
Expected: Camila is mentioned once, briefly, and is not the main character. No information is given about her travels.
- Larger models detect the false premise.
- Smaller models tend to accept the framing and hallucinate an answer.
🕳️ Non-Context Context
These are questions where the context contains no relevant information, and the model is expected to say so.
Example:
Question: Carl the football player was diagnosed with what? Expected Answer: No information about Carl’s diagnosis is provided in the text.
Model behavior:
-
✅ Correct (GPT-4o):
The context does not provide any information or diagnosis for Carl, the football player.
-
❌ Wrong (GPT-4.1-mini):
Carl the football player was diagnosed with mild persistent asthma, likely aggravated by a suspected viral upper respiratory infection.
🔍 This hallucination happens because the model confuses Carl with another patient.
Real-World Inference
This task is trivial for humans, but models often fail — particularly smaller ones. It’s a variation of aggregation and named entity recognition where you need to have real world inference capabilities. For example in the following task we test if the models catch this little nuance:
Task:
List all female characters mentioned.
Expected output:
Camila, Lucia, Marta, Jaya, Mum
- Most models miss "Mum", as they fail to associate the term with a female character when it is not presented as a proper name.
- Only 4 out of 13 models got this fully right: Sonnet-4 ,both Gemini 2.5 models and Grok-4.
Note: Smaller models often miss additional names beyond "Mum".
What's Next
We will continue improving our samples for each task category and regularly publish our findings. These results will also help guide our customers in selecting the right model for the right task.
Stay tuned for more blog posts on Opper Taskbench and our evaluation work!