Introducing Opper Taskbench - A Real‑World Benchmark for Task‑Oriented LLMs
By Jose Sabater -
Because great task completion starts with trustworthy measurement.
TL;DR
- Most benchmarks don't reflect real-world LLM usage. Opper TaskBench does.
- We believe tasks are the critical path, and core to any application
- Each "task" sample is one API call: structured in/out, real user goals.
- We evaluate using string-level, execution-level, and LLM-based methods.
- We break down results by accuracy, cost, model size, and task difficulty.
- More detailed breakdowns for each task coming soon
Why We Built Our Own Benchmark
At Opper, our mission is to deliver the most reliable task‑completion API for LLM workloads. Models and prompting strategies evolve quickly, but one principle stays the same: you can't improve what you don't measure.
But for us, it goes even deeper. In LLM-based systems, tasks are the critical path. If we don't get the task right-how it's framed, measured, and validated—then everything else we build on top of it is on shaky ground. Measurement isn't just about iteration; it's about ensuring that the core building block of the system actually works. That's why we built our own benchmark: not just to track performance, but to anchor everything we do in solid, task-level truth.
Academic benchmarks like MMLU or GSM‑8K are great for tracking raw model ability—but they rarely match the kinds of jobs our customers need done: summarising customer tickets, generating SQL from vague requests, or choosing tools in autonomous workflows.
That gap led us to create Opper TaskBench—a lightweight, evolving benchmark focused on real tasks, real context, and real constraints.
Disclaimer 🤝 TaskBench isn't meant to "beat" or replace existing academic benchmarks. Our goal is practical verification—helping customers see how models behave on the tasks they actually care about, with transparent methodology and no cherry‑picking.
What Exactly Is a "Task"?
At its simplest, a task is just one API call—prompt in, completion out.
Today, most real-world usage revolves around these atomic calls: summarising text, rewriting a sentence, or extracting a value. But we anticipate that this will change. As models improve and business needs evolve, more tasks will require deeper understanding, access to tools, and step-by-step reasoning.
Think of a future task like: "answer a support ticket." That single line hides a whole chain of reasoning:
- Understand intent ← what's the user asking?
- Retrieve & interpret context ← documentation, prior messages, policies
- Generate a grounded answer ← accurate, safe, brand-compliant
- Validate & structure ← return the answer in a usable format
TaskBench is designed to cover the full spectrum: from today's simple, atomic calls to tomorrow's complex, multi-step workflows.
Design Principles
- Task‑first, not model‑first — start from user value and measure what matters.
- Lightweight yet rigorous — minimal overhead, maximal signal; every sample is small, clear and directly tied to a real outcome.
- Evolves with the field — as models get smarter, we build tougher variants and brand‑new tasks.
Today we share some of the tasks
| # | Task | Capability Tested | Typical Customer Need |
|---|---|---|---|
| 1 | RAG & Context Recall | Accurate answers grounded in provided context | Knowledge‑base Support bots, policy lookup, internal knowledge Q&A |
| 2 | Natural Language → SQL | Text‑to‑query fidelity & schema reasoning | Analytics chat assistants, simplified database interfaces |
| 3 | Agentic Capabilities | Planning, tool choice, self‑diagnosis | Autonomous ticket triage, Agent workflows |
| 4 | Text Normalisation | Structured output from messy prose, different structures | Catalogue / product pipelines |
(More on the way: code generation, multilingual QA, doc parsing.)
Evaluators
Building high-quality datasets is one of the most critical tasks in AI evaluation. While designing clear input-output pairs is straightforward for some tasks, many real-world applications don't have exact matching outputs. This complexity requires a mix of evaluation strategies to extract meaningful insights from benchmarks.
Every task needs a fair referee. Here's how we evaluate outputs—automatically and scalably.
1. String-Level Evaluators
Fast, deterministic methods for text-based outputs:
- Exact match
- ROUGE/BLEU
- Regex heuristics
- Static analysis
📌 Example: For SQL generation, we verify structure using regex or exact format matching.
2. Execution-Level Evaluators
We execute the model's output to test functionality, not just syntax.
📌 Example: For SQL tasks, we run queries against mock DBs and compare results.
3. LLM-Based Evaluators
LLMs judge other LLMs on:
- Semantic accuracy
- Factual correctness
- Style or safety
We break down criteria (e.g., groundedness, completeness) and aggregate them into meaningful scores.They're particularly useful for open-ended or context-heavy tasks
👀 We recently published a guide on this approach:
Reference-Free LLM Evaluation with Opper
What's Coming in TaskBench
- Model Cards & Filtering — surface models by success rate, cost, latency, and more
- Prompt tuning — auto-search for better instructions
- Example synthesis — how to generate few-shot examples and how to use them
- Cost dashboards — show $ per success, latency, token usage
- Learning workflows — teach users how to evaluate and prompt well
- Open reference tasks — share best-practice templates for benchmarking
Everything ties into the Opper API, so you get the benefits—without the overhead.
Early Results
Before we dive into the charts, here are two quick wins that already stand out:
- Reasoning boosts accuracy. Asking the model to write down its thought process first—often called chain-of-thought prompting—reduces hallucinations and lifts task scores across the board.
- Structured output removes friction. Opper lets you describe the exact JSON shape you need, so the response is ready for immediate use—no regexes, no guesswork.
A Tiny Demo of Both Ideas
from opperai import Opper
from pydantic import BaseModel, Field
import asyncio
import os
opper = Opper(http_bearer=os.getenv("OPPER_API_KEY"))
class Discount(BaseModel):
explanation: str = Field(
...,
description="think step by step about the discount calculation before answering"
)
original_price: float
discount_percent: float
final_price: float
async def main():
response= await opper.call(
name="calculateDiscount",
input="This winter jacket costs $120 and is on sale for 25% off.",
output_schema=Discount
)
print(response.json_payload["explanation"])
# Sample reasoning:
# The original price of the jacket is $120. A 25% discount means we need to calculate 25% of $120, which is $120 * 0.25 = $30.
# Subtracting this discount from the original price gives us the final price: $120 - $30 = $90.
print(response.json_payload) # original_price=120.0 discount_percent=25.0 final_price=90.0
asyncio.run(main())
The output arrives as a validated Room object, complete with the model's internal reasoning—making debugging and evaluation straightforward.
Stay tuned: in upcoming posts, we'll share detailed side-by-side comparisons (complete with visualizations) of model behavior with and without reasoning steps. For now, all the results you see here use a consistent, reasoning-enhanced generation approach across all models.
And now—onto the long-awaited results.
Unsurprisingly, most models perform well on straightforward tasks. But as complexity increases, we begin to see clear differences. Tasks that require decision-making, contextual reasoning, or structured normalization begin to expose model limitations.
Each task includes around 30 carefully designed samples. Each sample has a defined input (often with rich context or long instructions) and a clearly expected output. All models are prompted with the same simple instructions, for example like this:
{
"instructions": "You are a helpful assistant that will answer the users question using the given context",
"context": "required context to perform the task (typically a set of documents)",
"question": "How many cities are mentioned in the context?"
}
What Are We Seeing?
- SQL generation is the most stable task: models consistently succeed, likely due to the highly structured nature of SQL and clear expected patterns.
- Agentic tasks—where models must make decisions or plan actions—are the most challenging. The open-ended nature of these tasks leaves room for many valid outputs, which increases the chances of mistakes.
- Context-heavy questions often expose hallucinations or shallow reasoning. Some models struggle when the context is noisy or when the task demands real-world inference.
- For example in a passage with several named characters, some models fail to identify "mum" as a female character—likely due to lack of explicit naming.
- Normalization tasks, especially those expecting natural language to follow a rigid schema, are surprisingly tough. Even strong models struggle when the output format is nuanced but not explicitly structured in code.
In our charts scores range from 0.0 to 1.0, where 1.0 means the model got all test cases right. For example, a model scoring 0.8 on a task with 30 samples got 24 correct.
We benchmarked a curated subset of models from Opper's 85+ available endpoints (as of July 12, 2025) to keep the comparisons readable:
Model Performance Highlights
Grok-4 dominates the leaderboard when averaging across all tasks followed closely by the other reasoning models. Both Gemini 2.5 Pro and Flash Lite also perform similarly across all tasks, achieving very high accuracy.
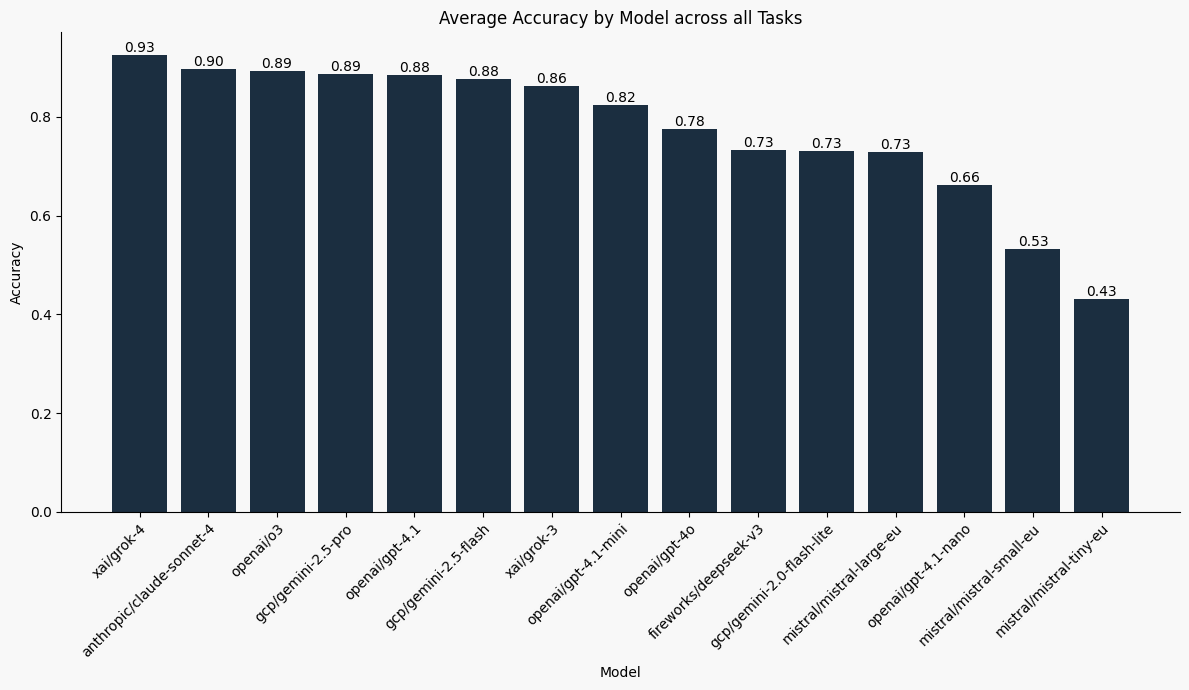
Across the board, high-end models perform impressively.
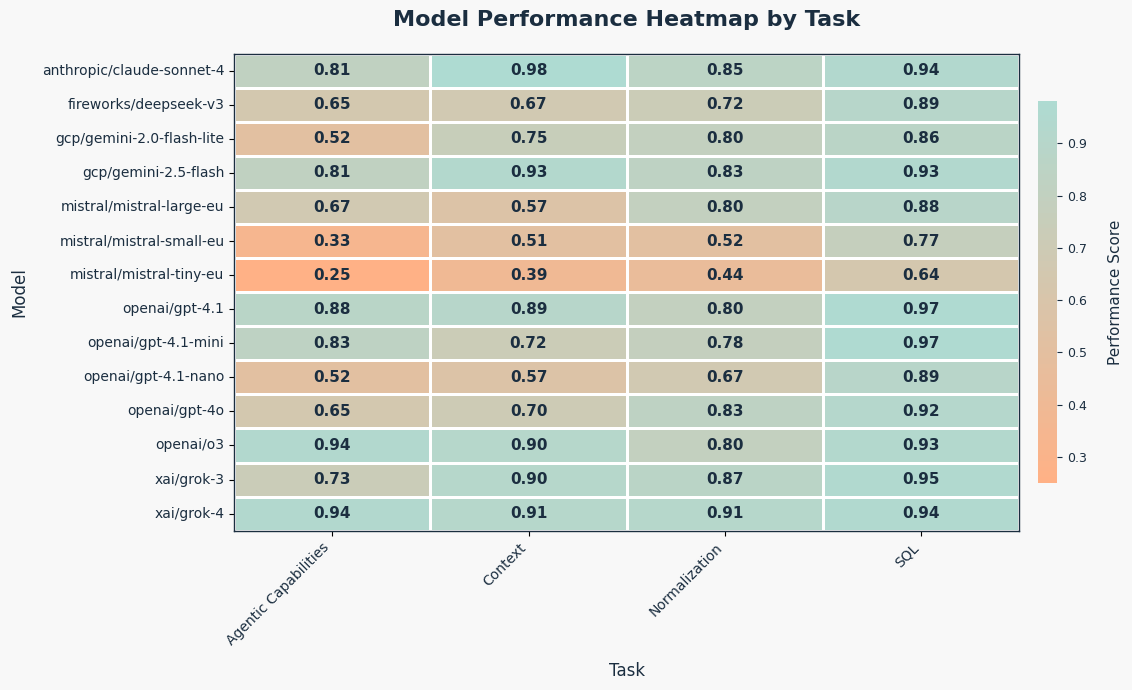
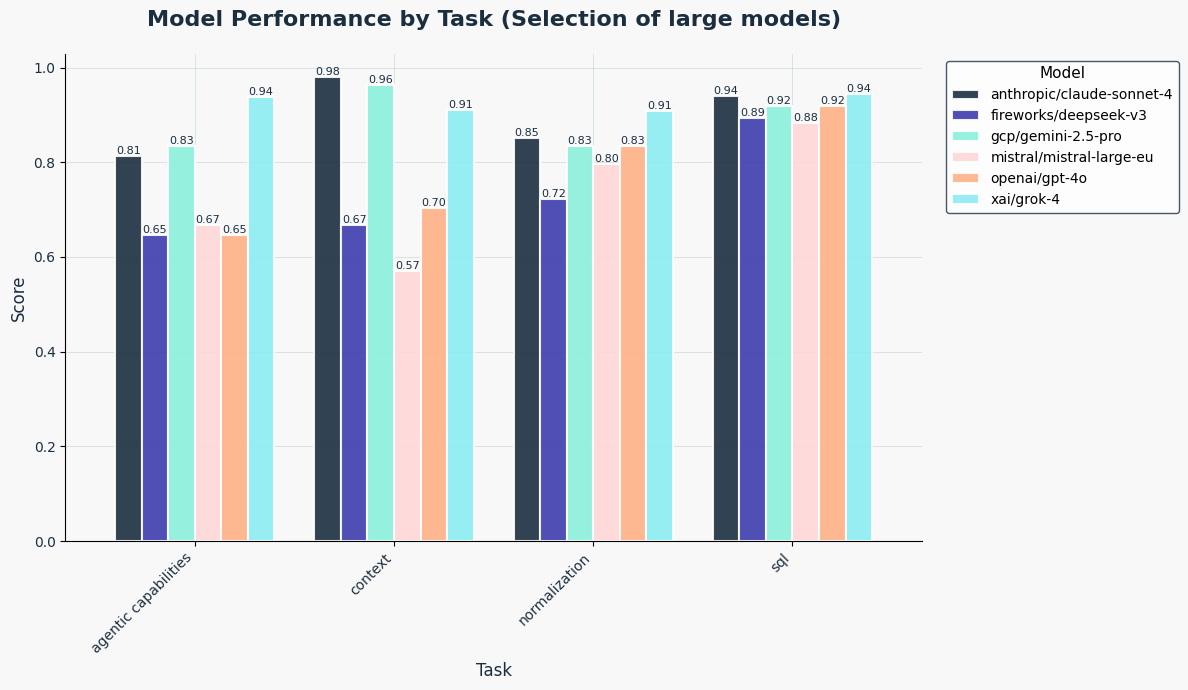
Among large models:
- Performance varies by task — no single model is best at everything.
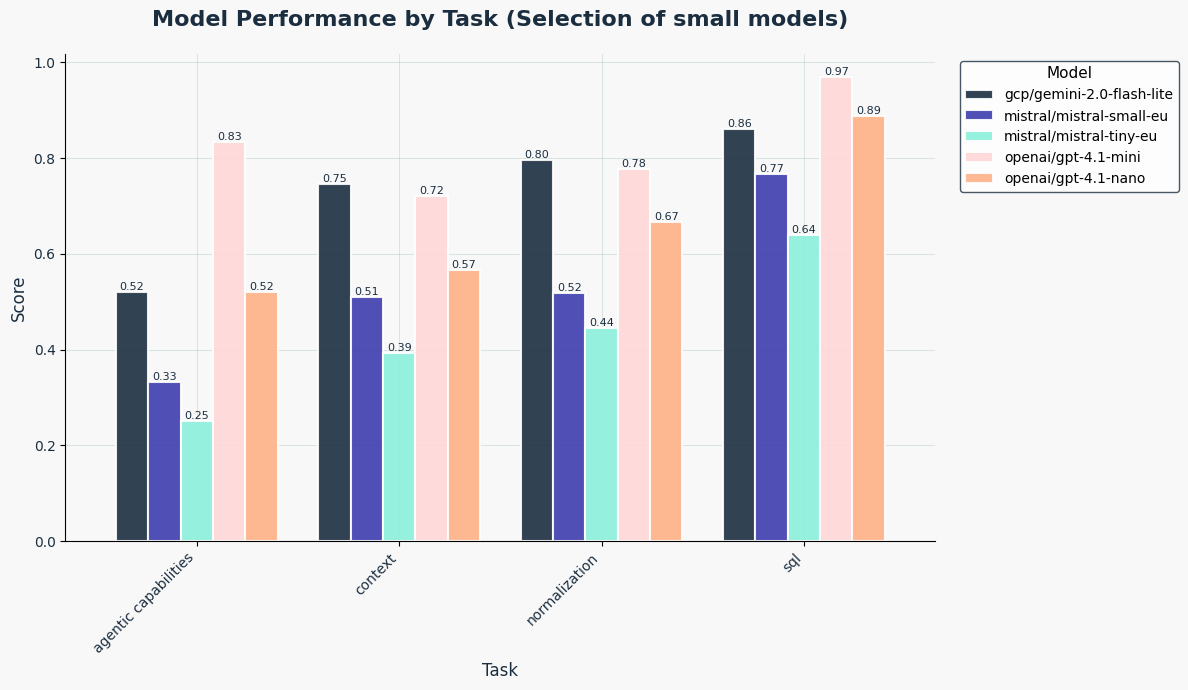
Among smaller models, strong contenders include:
- GPT‑4.1‑mini
- Gemini Flash lite
While the Mistral series generally trails behind.
Zoomed-In Matchups:
In some cherry-picked comparisons, smaller models get surprisingly close to larger ones—raising important questions around cost-performance tradeoffs.
In particular on the SQL tasks or when comparing gpt-4.1 mini with its larger brother 4.1:
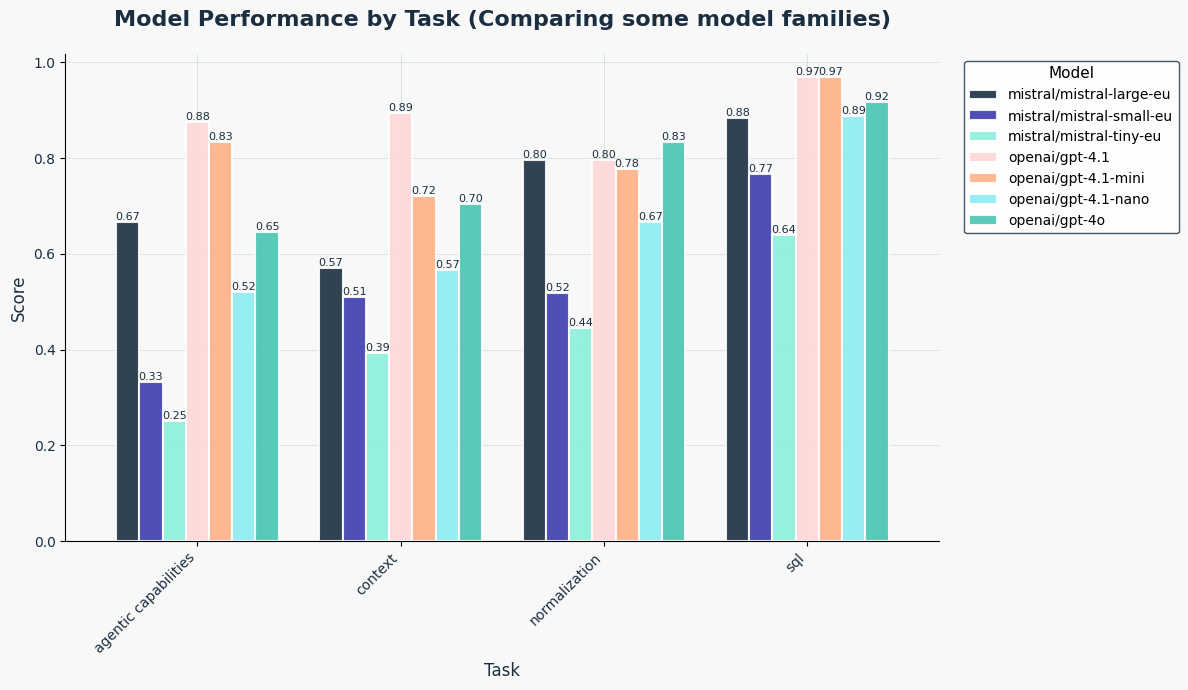
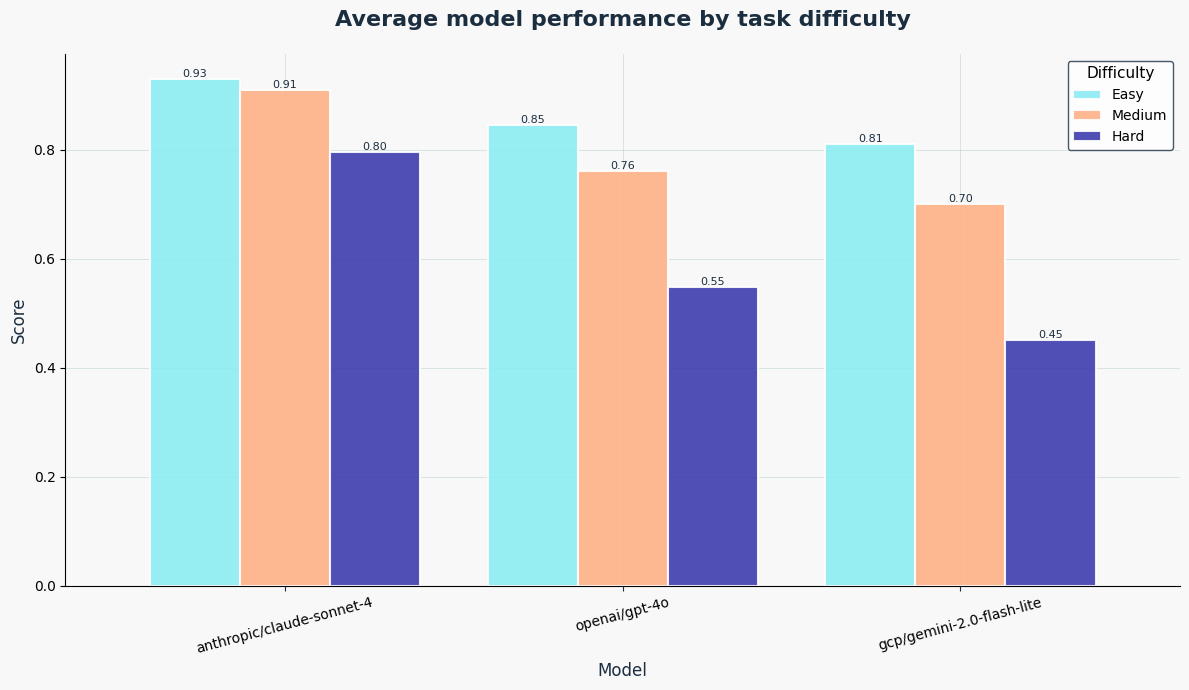
We also analyzed performance by task difficulty. Difficulty levels are human-rated estimates of what we expect should be:
- Easy: Direct lookups, simple structure, low ambiguity
- Medium: Moderate reasoning, slightly more contextual interpretation
- Hard: Open-ended tasks, real-world inference, or multi-step decisions
The below graphs are averages across all tasks for each of these models.
How Does Cost Factor In?
Choosing the best model isn’t always about accuracy alone. In real-world use, teams must weigh:
- Cost per successful output
- Latency and speed
- Tolerance for error or hallucination
To help make informed decisions, we’re building cost/latency dashboards that highlight:
- Token efficiency
- Trade-offs between verbosity and precision
Some models are naturally more verbose—for instance, responding with full paragraphs instead of structured answers. This verbosity can drive up token usage, and therefore cost. That’s why we emphasize task-specific optimization—choosing the best model per task, not just defaulting to the largest or newest.
And not all tasks are created equal. Writing a SQL query requires more output than answering “true” or “false.” So while this blog shows overall averages, the full version of TaskBench provides per-task graphs, which are ultimately more actionable.
Still, here’s an early look at the aggregate trends: combining total output tokens and average accuracy across all tasks, to give a rough picture of where each model stands in terms of efficiency and performance.
Cost Metrics (Opper pricing, as of June 13, 2025)
Raw accuracy doesn’t tell the full story—cost per output matters, especially at scale.
-
usd_per_call -> The average cost to run one sample in a task.
Computed as:
mean_output_tokens × price_per_million_tokens
Other relevant metrics include:
- Average Output Tokens: Mean number of output tokens per sample (task-dependent), reflects model verbosity
- Accuracy: Overall proportion of correct responses.
Here’s an early look at how popular models compare:
| Model | Accuracy | Average Output Tokens | USD per MToken | USD per Call |
|---|---|---|---|---|
| xai/grok-4 | 0.925 | 1568 | 15 | 0.0235 |
| gcp/gemini-2.5-pro | 0.887 | 896 | 10 | 0.009 |
| openai/o3 | 0.892 | 756 | 8 | 0.0061 |
| gcp/gemini-2.5-flash | 0.877 | 725 | 2.5 | 0.0018 |
| xai/grok-3 | 0.863 | 315 | 15 | 0.0047 |
| anthropic/claude-sonnet-4 | 0.896 | 268 | 15 | 0.004 |
| openai/gpt-4.1 | 0.884 | 210 | 8 | 0.0017 |
| openai/gpt-4.1-mini | 0.825 | 193 | 1.6 | 0.0003 |
| openai/gpt-4o | 0.775 | 191 | 10 | 0.0019 |
| openai/gpt-4.1-nano | 0.661 | 160 | 0.4 | 0.0001 |
| mistral/mistral-small-eu | 0.532 | 158 | 0.3 | 0 |
| mistral/mistral-tiny-eu | 0.432 | 152 | 0.25 | 0 |
| fireworks/deepseek-v3 | 0.732 | 152 | 0.9 | 0.0001 |
| mistral/mistral-large-eu | 0.729 | 144 | 6 | 0.0009 |
| gcp/gemini-2.0-flash-lite | 0.731 | 135 | 0.3 | 0 |
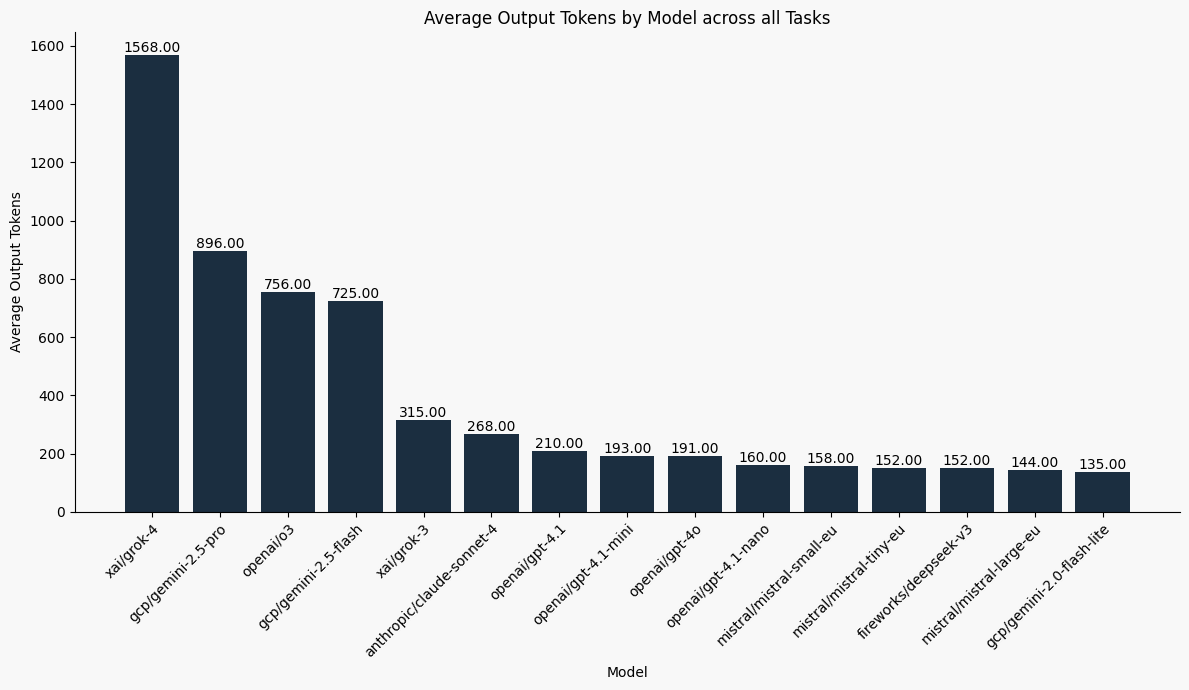
A Note on Reasoning Models
All models were run with their default settings, meaning some include server-side reasoning out of the box. Notably:
- Grok-4, o3, and Gemini-2.5-Flash include enhanced reasoning steps by default, which boost accuracy but also inflate output tokens and cost.
- Anthropic models offer optional reasoning but are set to “off” by default.
With Opper, setting all these options is extremely easy! Check our docs
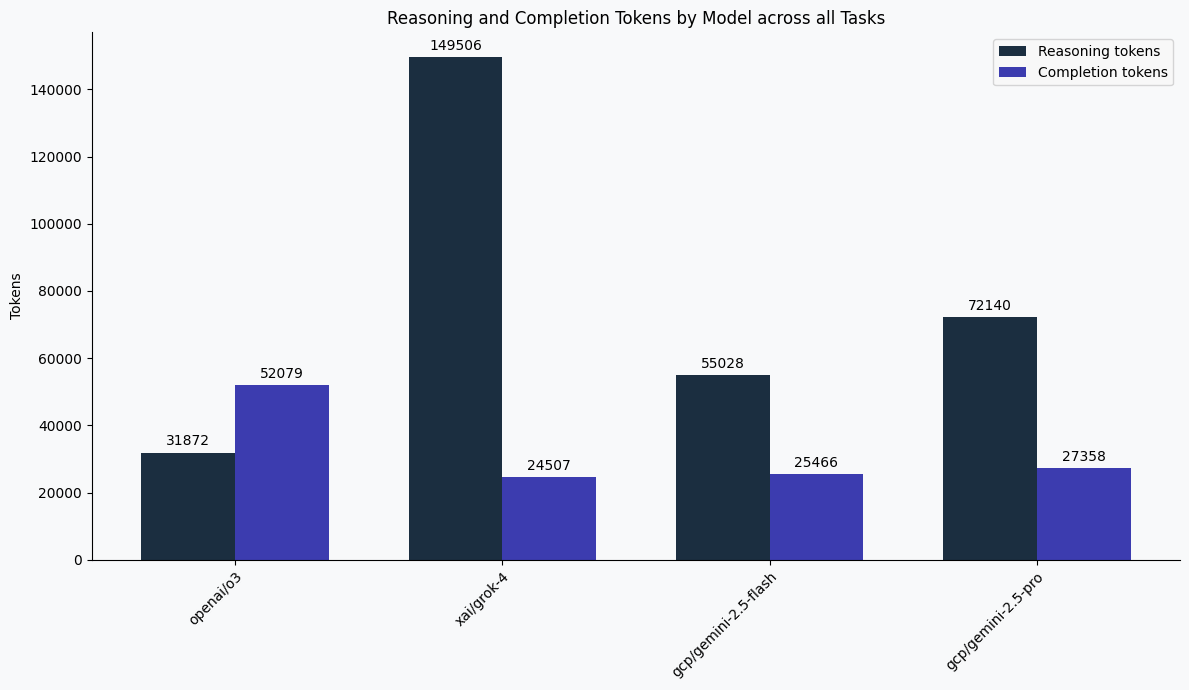
Verbose reasoning models like Grok-4 generate many tokens dedicated to internal thinking steps, not just final answers. This boosts correctness but comes with a higher token cost—something users should be aware of when budgeting for production use.
What's Next?
Curious how we define and score each task? Want to see real examples of agentic reasoning, context comprehension, or structured normalization?
We'll cover all of that in upcoming deep dives—exploring:
- Methodology and human alignment
- Sample design
- LLM-based evaluation strategies
- Lessons from building practical benchmarks
Stay tuned!
Join us at → Opper AI