Introducing Delvin: State of the art bug fixing agent
By Alexandre Pesant -
Delvin is an agent fixing issues from the SWE-Bench dataset and achieving state of the art accuracy (23%) on SWE-Bench Lite with very simple code leveraging the Opper SDK.
Note: OpenDevin reached 25% accuracy on the SWE-Bench Lite dataset just a day later!
SWE-Bench
SWE-Bench is a dataset of more than 2000 issues and fixes collected from popular python projects on GitHub, which can be used to test systems ability to fix bugs by verifying their submitted patches against the PRs unit tests. A smaller version, SWE-Bench Lite, contains 300 entries and is much cheaper to use for evaluation.
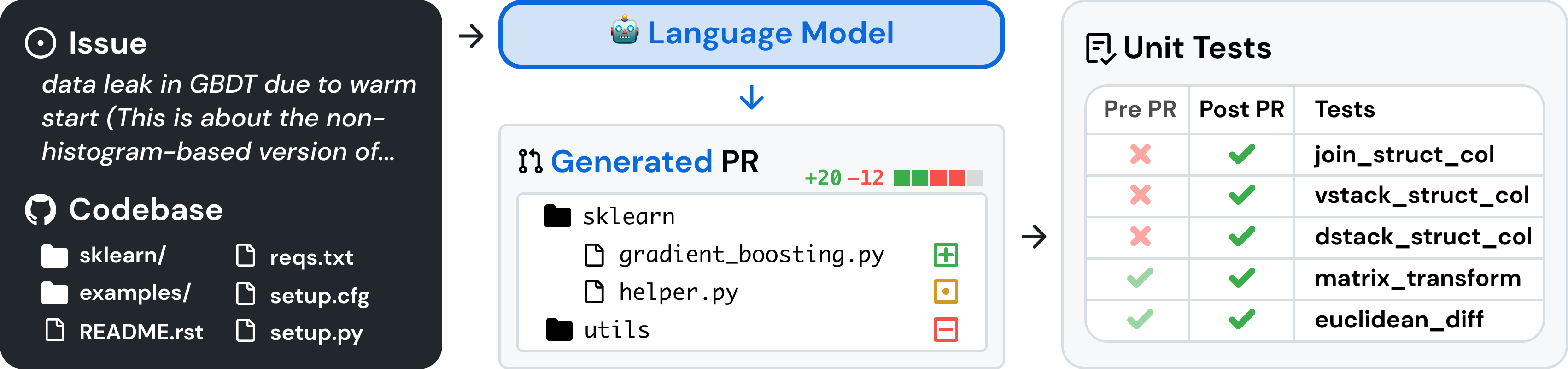
We recently ran a hack week at Opper and I decided to run a super simple agent that would try to fix issues from the Lite dataset.
Delvin
Delvin is an agent written in Python with the Opper SDK. Its input is the issue to solve (alongside the project's code) and its output is a patch that should fix the issue.
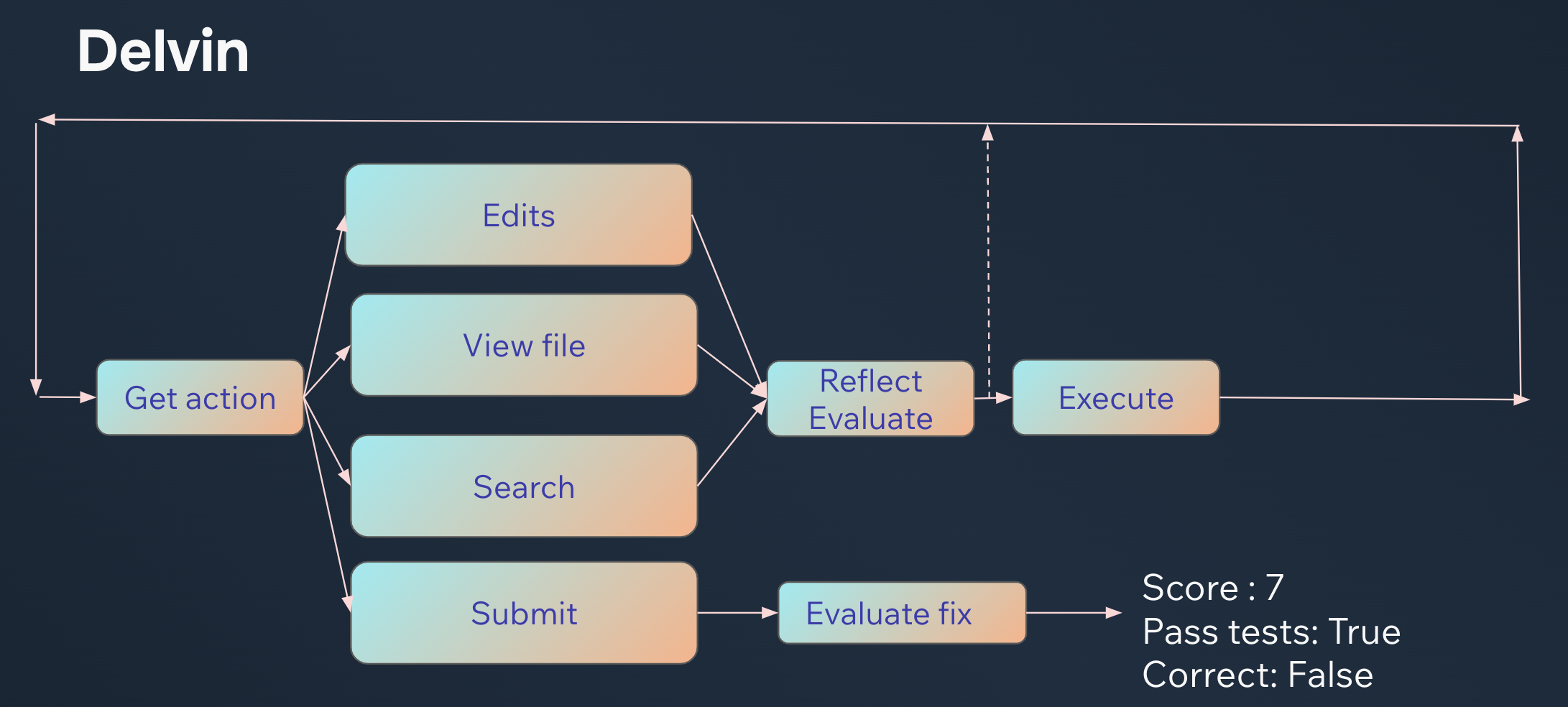
At its core, Delvin runs a loop where we select an action to run given the problem to solve and the history of actions we've taken so far (the agent trajectory).
class Action(BaseModel):
thoughts: str = Field(
...,
description="Step by step reasoning about the action to take. Make sure you have viewed all the necessary code before making an edit. It's always okay to look at more code.",
)
learning: Optional[str] = Field(
...,
description="A learned fact about the repo and issue. Could be about a specific function or a pattern in the code.",
)
action_name: Literal[
"search",
"edits",
"submit",
"view_file",
] = Field(..., description="The action to take.")
action_input: Union[
Search,
Edits,
Submit,
ViewFile,
]
class Trajectory(BaseModel):
"""The trajectory of the agent's actions."""
actions: list[ActionWithResult]
gained_knowledge: list[str] = Field(default_factory=list)
from opperai import fn
# get_action is called in a loop until the agent decides to submit a patch or the maximum number of actions is reached
@fn()
async def get_action(
trajectory: Trajectory, problem: str, other_info: str
) -> Action:
Leveraging the Opper SDK, we can define exactly how we want the agent to behave and list the actions it can take. No parsing, no exotic DSL. Just Python. In this case, the agent can search for a file, view a file, make edits, and submit a patch. Before selecting an action, we make the agent describe its thoughts and output potential learnings that could be useful for future actions.
Searching
class Search(BaseModel):
"""Search for a regex in the repository. Will search through file names and their contents."""
regex: str = Field(
...,
description="Regex to search for. Matches will be returned",
)
The search action combines file search and content search. We return the top 100 matches for both file names and file contents.
First 100 files containing def\s+from_json:
- pydicom/dataset.py line 2225 : def from_json(
- pydicom/dataelem.py line 230 : def from_json(
First 100 filenames matching def\s+from_json:
No file names containing def\s+from_json found.
Viewing Files
class ViewFile(BaseModel):
"""View a file in the repository. Don't hesitate to call this action multiple times to move around the file and to get more context."""
file_path: str
cursor_line: int = Field(
...,
description="The line number to start from.",
)
before: int = Field(
ge=100,
description="Number of lines to display before the cursor line.",
)
after: int = Field(
ge=100,
description="Number of lines to display after the cursor line.",
)
By calling the view file action, the agent can open a file given a path and decide where to look. We return to the agent the outline of the file (Definitions of top level variables/functions) and the code around the cursor line.
# Outline:
63: class PrivateBlock:
86: def __init__(
109: def get_tag(self, element_offset: int) -> BaseTag:
131: def __contains__(self, element_offset: int) -> bool:
137: def __getitem__(self, element_offset: int) -> DataElement:
160: def __delitem__(self, element_offset: int) -> None:
178: def add_new(self, element_offset: int, VR: str, value: object) -> None:
201: def _dict_equal(
221: class Dataset(Dict[BaseTag, _DatasetValue]):
373: def __init__(
...
# File content:
2126| The file meta information was added in its own section,
2127| if :data:`pydicom.config.show_file_meta` is ``True``
2128|
2129| """
2130| return self._pretty_str()
2131|
2132| def top(self) -> str:
2133| """Return a :class:`str` representation of the top level elements. """
2134| return self._pretty_str(top_level_only=True)
2135|
2136| def trait_names(self) -> List[str]:
2137| """Return a :class:`list` of valid names for auto-completion code.
2138|
2139| Used in IPython, so that data element names can be found and offered
2140| for autocompletion on the IPython command line.
2141| """
2142| return dir(self)
2143|
2144| def update(
2145| self, dictionary: Union[Dict[str, object], Dict[TagType, DataElement]]
2146| ) -> None:
2147| """Extend :meth:`dict.update` to handle DICOM tags and keywords.
2148|
2149| Parameters
...
The balance between adding relevant context for the investigation and not overwhelming the agent with too much information isn't trivial, and I certainely could do more comparisons there to see what works best.
Editing files
Editing files was by far the trickiest part. I first tried to get the agent to output correct diffs but saw too many issues with wrong line numbers or indentations not being followed. I ended up with the following Edit Action
class Edit(BaseModel):
"""
Edit a file in the repository by replacing a code block.
Before applying edits, validate the existence and correct implementation of any new functions or variables introduced.
Make sure you have seen all the code necessary to make the edit. View entire function bodies first.
The edited code CANNOT refer to unknown variables or functions. NO TODOS or placeholders.
Edits can only be done in files and lines that have already been viewed.
You MUST remove line numbers from the new code and keep indentation intact.
"""
file_path: str = Field(..., description="Path of the file to edit.")
seen_all_needed_code: bool = Field(
...,
description="Have you seen all the code needed to make the edit? Did you view the entire body of the function you are about to modify? You must be SURE.",
)
no_other_file_viewing_needed: bool = Field(
...,
description="Did you take a good look at other methods/classes in the file that were provided in the file outline? Are you sure you don't need anything else? You must be SURE.",
)
edit_contains_all_needed_code: bool = Field(
...,
description="Will you write all the code you need to replace the old code? You must guarantee that you will not take shortcuts and be thorough.",
)
short_description: str = Field(
...,
description="A short description of the edit where you identify the lines to edit and what to do.",
)
code_to_replace: str = Field(
...,
description="The code that will be replaced. Keep line numbers intact.",
)
start_line: int = Field(
..., description="The index of the first line that will be replaced."
)
end_line: int = Field(
...,
description="Line number to end editing at. All lines betwee start_line and end_line are replaced.",
)
new_code: str = Field(
...,
description="The new code to replace the old code with, WITHOUT line numbers. Indentation MUST be correct. Keep all leading whitespaces and newlines intact. Example:' def new_action(self):\n pass\n'",
)
no_unknowns: bool = Field(
default=False,
description="If true, the edited code does not refer to unknown variables or functions. The edited code does not contain placeholders for future implementation.",
)
That's a pretty massive action! The idea here is to force the agent fill a checklist and combat GPT-4 Turbo's "lazyness" before making an edit and providing the code to replace. When applying the edit, we take the code to replace and add a few lines before and after to our editing function, which rewrites the entire code block. This prevents a lot of indentation issues and makes the agent's output more reliable.
@fn
async def smart_code_replace(code_snippet: str, to_replace: str, new_code: str) -> str:
"""
Given a code snippet, replace the code given in the to_replace variable with the new_code variable and return the fully edited code.
It is possible that there are slight indentation issues and small mistakes in the provided to_replace and new_code variables.
Return a fully syntactically correct code snippet. Focus on indentation, it might be incorrect.
"""
smart_code_replace is an opper function that applies edits and can potentially fix obvious mistakes in the code we're supposed to insert.
Feedback is key
Once edited, the code is linted with Ruff. We're specifically looking for cases where the agent inserted references to code that doesn't exist (F821). The linting output is added to the agent's trajectory and the agent can decide to submit the patch or continue editing.
To give more signal to our agent, we run each action about to be taken through a reflection function. The goal is to simply take a step back and verify whether we're on the right track or stuck in a reasoning loop.
class Evaluation(BaseModel):
"""
Evaluation of the action an agent is going to take given its trajectory.
"""
observations: str = Field(
...,
description="Detailed observations of where we are and if the action makes sense.",
)
right_track: bool = Field(
..., description="Whether the action is on the right track."
)
feedback: Optional[str] = Field(
None,
description="Feedback for the agent if not on the right track. Could be used to course correct.",
)
@fn
async def evaluate_action(
trajectory: Trajectory,
action_to_evaluate: Action,
possible_actions: str,
problem: str,
) -> Evaluation:
"""
Evaluate the action an agent is going to take given its trajectory and the actions it can take.
You are given the problem it is trying to solve.
Be very diligent in evaluating the action, especially if it is an edit.
You can only affect the action that is being evaluated, not the trajectory. Focus on whether the action makes sense and propose
an alternative if it doesn't.
"""
Naive LLM-powered agents implementing simple thoughts-action-observations loops have very poor planning skills and easily get stuck in reasoning loops, so it's primordial to be able to give clear and actionable feedback to the agent.
Road to 30+% accuracy

As the above table shows, SWE-Agent gets a 32% pass@6 accuracy on the SWE-Bench Lite dataset. There's lots of room for either adding some kind of brute-force majority voting (e.g launch 6 agents in parallel and take the most common diff) or doing search-based optimization on the agent's actions to improve the accuracy. Given GPT-4o's performance with Delvin, achieving a 30% pass rate seems very likely.
On top of that, Delvin is not using Opper's few shot retrieval capabilities (see this blog post), which would likely increase the accuracy of the existing architecture by providing correct examples in prompts.
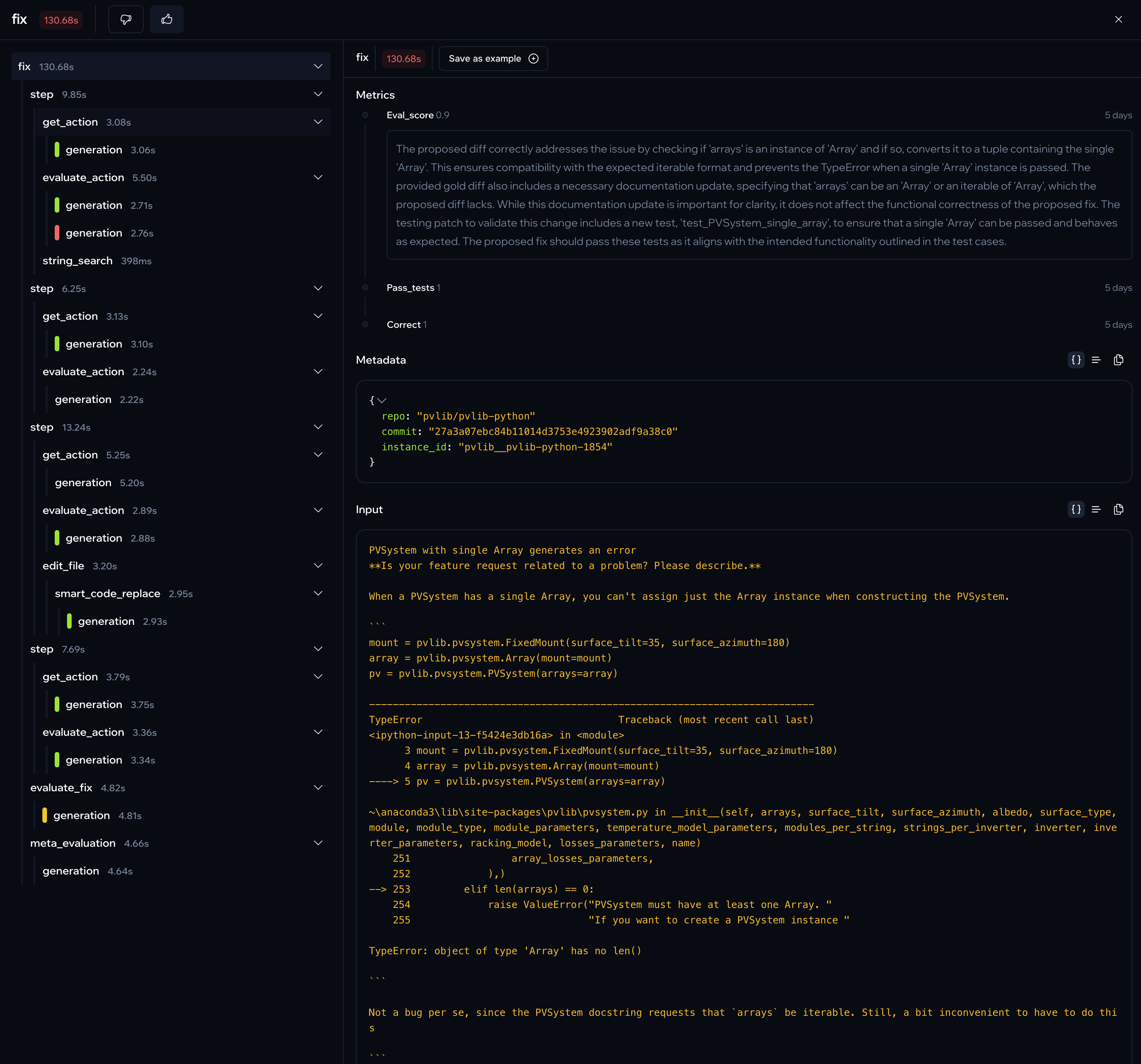
An example of a successful run of Delvin. As you can see, it would be quite hard to keep track of what's going on without the tracing view :)
Conclusion
If you want to build agents:
- Give GPT-4o a shot: it's a lot less "lazy" and will not be afraid to go through longer trajectories.
- Make actions as simple as possible: the more options your agent has, the more likely it is to follow the wrong path. You might not even need an agent. Can you program the flow instead?
- Environment feedback is key: put as many guardrails as possible to get real, actionable feedback. Linting errors, unit tests, etc.
- Use reflection: verify your agent's state and give feedback on its reasoning.
- Focus on writing code! If you're stuck writing parsing code you'll quickly get stuck in low-level details. Think in functions: what's the input? What's the output?
- Trace what's happening: tracing is not a nice-to-have for building AI flows, it's a must. It makes debugging and understanding the agent's behavior much easier.
Delvin is open source and available on GitHub.