Examples are all you need: getting the most out of LLMs part 2
By Alexandre Pesant -
In the previous post we looked at how leveraging structured output and Chain-Of-Thought prompting greatly improved the accuracy of GPT-3.5 Turbo on the GSM8k benchmark (from 25% to 71%). In this post we'll look at how to easily add high quality examples to our prompts to get even higher accuracy.
An example is worth a thousand tokens
Prompting LLMs is hard: Do this. DO NOT use backticks. You MUST remember to follow the 2 steps. You SHOULD NOT forget to do this. It is CRUCIAL to use this tool.
Bigger and smarter models often perform better 0-shot (without examples) but there are limits to what one can infer from the prompt alone. And this applies to humans as well! It can be extremely hard to understand what one is supposed to do even if instructions are relatively clear...We've all been there when playing a new board game :) Much easier to get going and understand the rules by playing a few rounds.
Examples are an incredibly powerful tool to guide LLMs in the right direction and will very often vastly outperform carefully crafted prompts. How can we add that?
GSM8k revisited
Let's go back to where we left of the GSM8k benchmark.
from pydantic import BaseModel, Field
class MathSolution(BaseModel):
"""A math solution with step-by-step reasoning and final answer"""
thoughts: str = Field(..., description="step-by-step solving of the problem")
value: int = Field(description="The final numerical answer to the math problem")
@fn(model="openai/gpt3.5-turbo")
async def predict_cot(question: str) -> MathSolution:
"""Solves math problems"""
The GSM8k benchmark not only provides the solution to math problems, but the rationale behind it as well. Let's take some examples from the dataset and add them to our function docstring.
@fn(model="openai/gpt3.5-turbo")
async def predict_cot(question: str) -> MathSolution:
"""
Solves math problems
Examples:
- Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Thoughts: Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.
Answer: 72
- Question: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?
Thoughts: Weng earns 12/60 = $<<12/60=0.2>>0.2 per minute. Working 50 minutes, she earned 0.2 x 50 = $<<0.2*50=10>>10.
Answer: 10
- Question: James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?
Thoughts: He writes each friend 3*2=<<3*2=6>>6 pages a week So he writes 6*2=<<6*2=12>>12 pages every week That means he writes 12*52=<<12*52=624>>624 pages a year
Value: 624
"""
Let's rerun our evaluator on the GSM8k benchmark:
calculate_pass_rate(results_manual_examples)
>>> Pass rate: 72.00% (between 72-74% depending on the runs)
A surprisingly low improvement to be honest!
Some potential reasons for this:
- The examples are not diverse enough.
- We didn't add enough examples: adding more can improve accuracy, but can quickly reach a point of diminishing returns.
- Human rationale formatting: The human rationales use a notation like
<<48/2=24>>24for intermediate steps. - We've indented the examples in the docstring but as we generate JSON structured output, it would be better to provide examples formatted exactly as what the model should generate.
- The rationales aren't really relevant to how the model "thinks". Are we using the right words? How should we write operations?
We certainely could find better examples in the dataset, but let's try a different approach.
Synthetic examples and the teacher student pattern
While the dataset we're using is great for this exercise, it's hardly representative of real world tasks. Often we'll ask models to generate many "chain-of-thought"-like outputs in order to guide it. Writing these by hand can help but as the pipelines get more complex, it becomes time consuming and sub optimal.
# A plausible class representing the choice made by an AI agent.
# Quite hard and tedious to manually write examples!
class AgentAction(BaseModel):
"""The action the agent should take"""
observations: str = Field(..., description="The observations the agent has made")
thoughts: str = Field(..., description="Step by step reasoning of the agent")
action: str = Field(..., description="The action the agent should take")
learning: str = Field(..., description="The learning the agent should take from the action")
A much more scalable approach is to use synthetic examples and leverage the teacher student pattern. Use a more expensive, smarter and slower models to demonstrate to a cheaper model how to solve a problem, using "LLM language".
So let's create a new function, predict_cot_with_examples and use the best model from Anthropic, Claude 3 Opus, as our teacher.
@fn(model="anthropic/claude-3-opus")
async def predict_cot_with_examples(question: str) -> MathSolution:
"""Solves math problems"""
Each Opper function is tied to a dataset. A dataset is list of input/output pairs one can control via our SDK and API. Let's run a few entires from our training set through our new function and save them to the function's dataset.
from opperai import AsyncClient
from opperai.types import ChatPayload, Message
op_client = AsyncClient()
for example in training[0:20]: # We will generate 20 demonstrations
# We will use our lower level `chat` API to call our function and get the span ID of the generated example
payload = ChatPayload(messages=[Message(role="user", content=example["question"])])
response = await op_client.functions.chat("predict_cot_with_examples", payload)
# Save the example to the function's dataset (Opper lets you do that in our tracing UI as well!)
await op_client.spans.save_example(response.span_id)
What's going on here? We iterate over the 20 first items in our training set, and for each question, we call our new function with the question as input.
The generated solution (a JSON object that maps to the MathSolution class) is saved to the function's dataset.
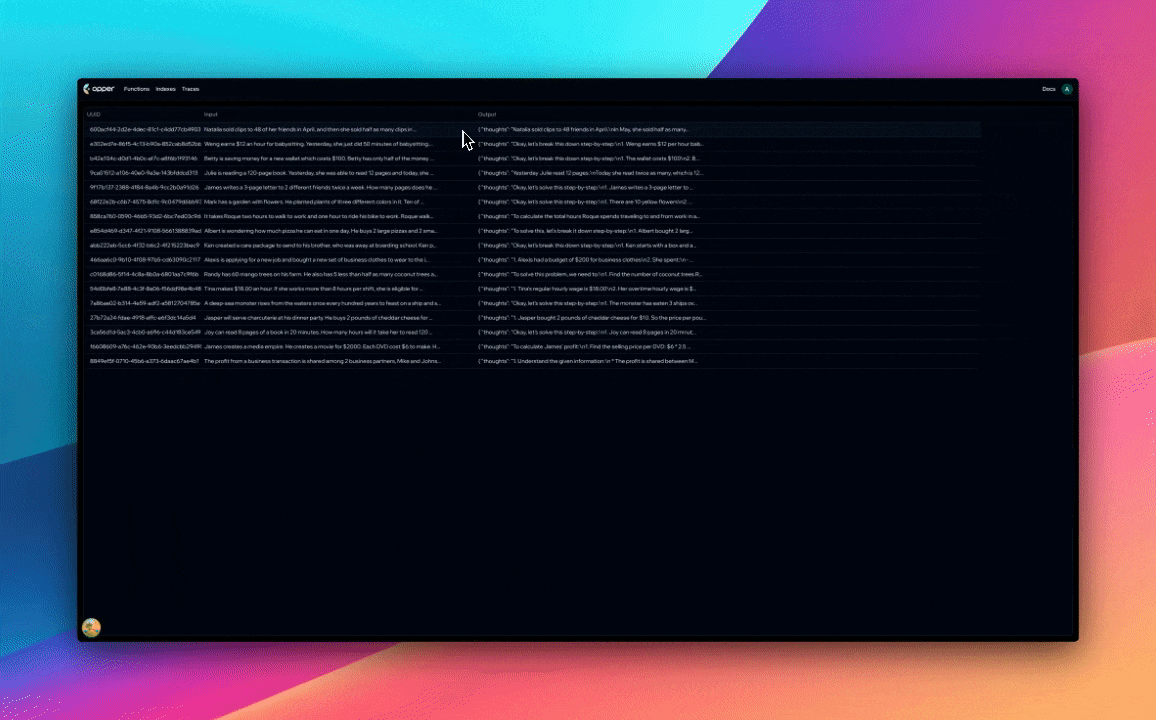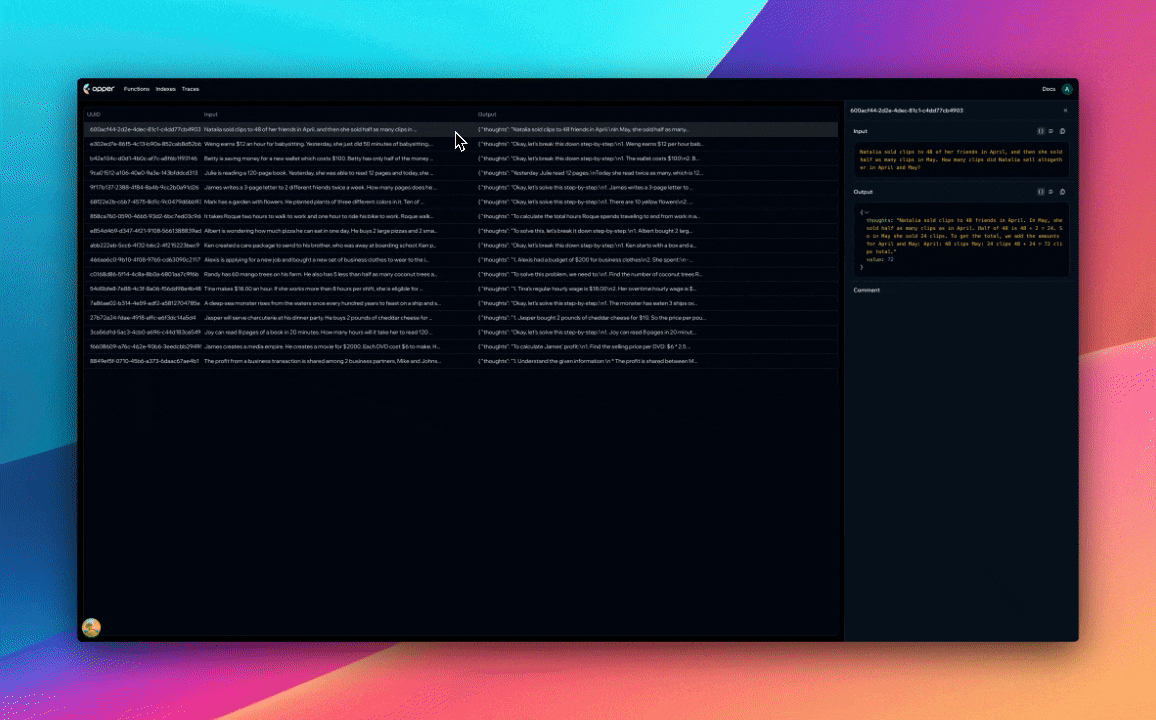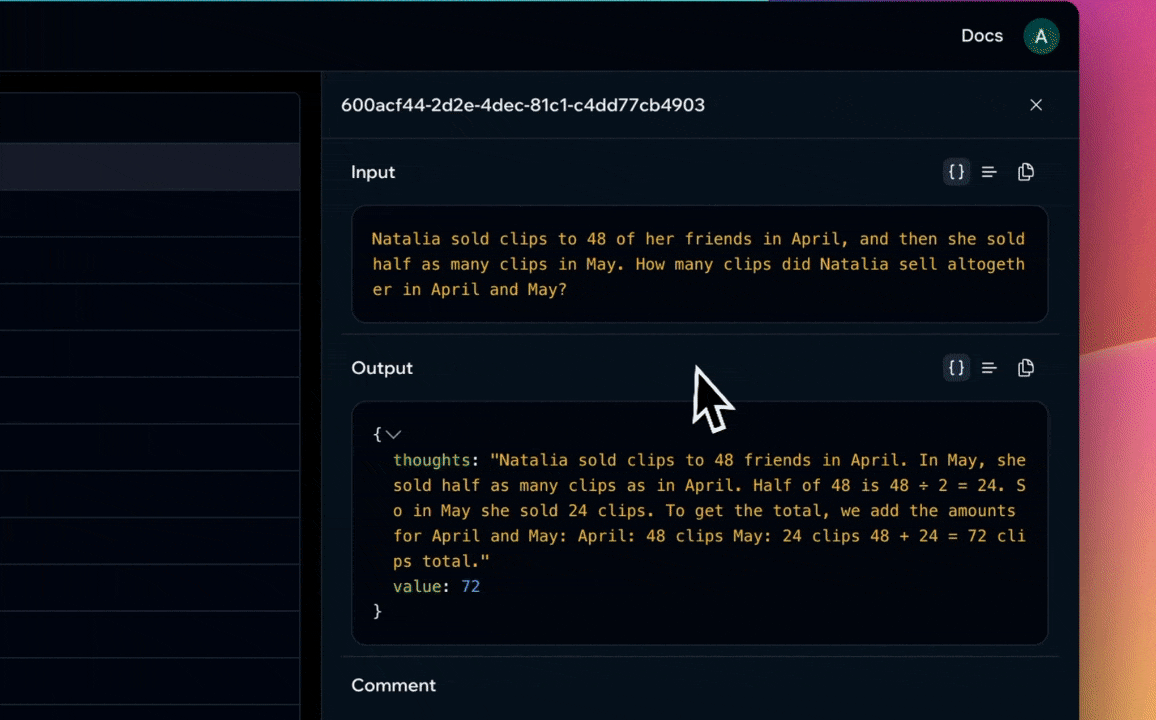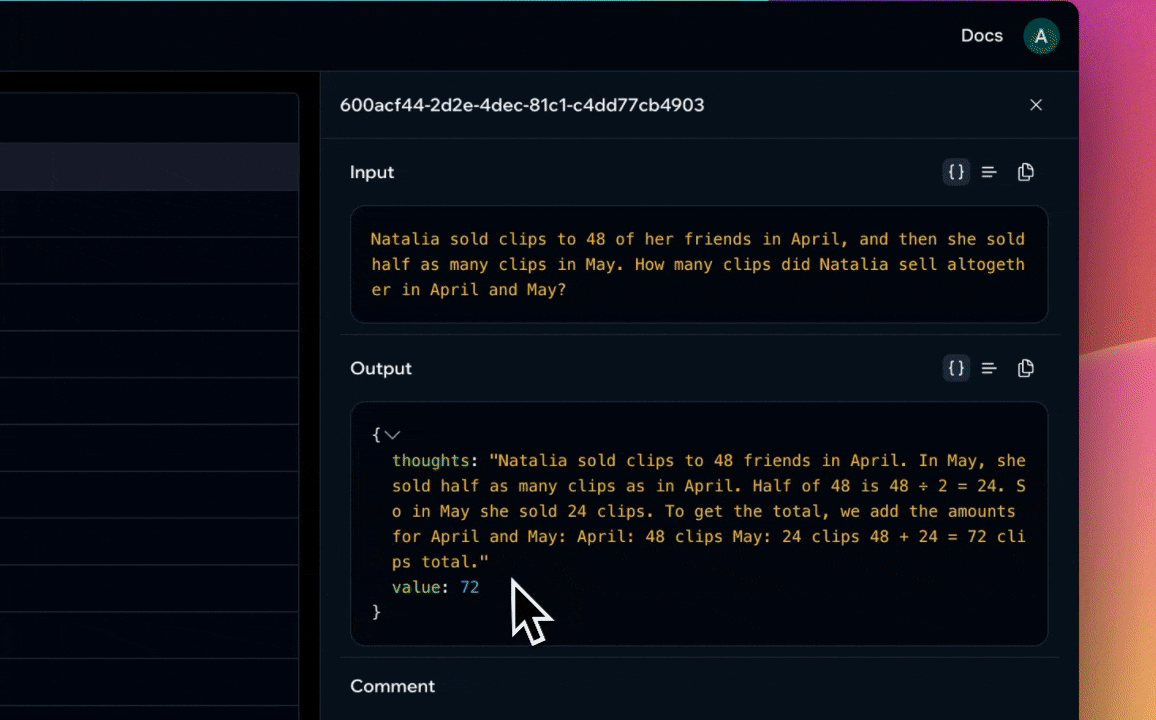
Our function now has 20 examples in its dataset, each containing chain-of-thought and final answer.
Each Opper function can be configured to dynamically retrieve relevant examples from its dataset when called. The examples are added to the prompt sent to the model. This technique is called few shot retrieval.
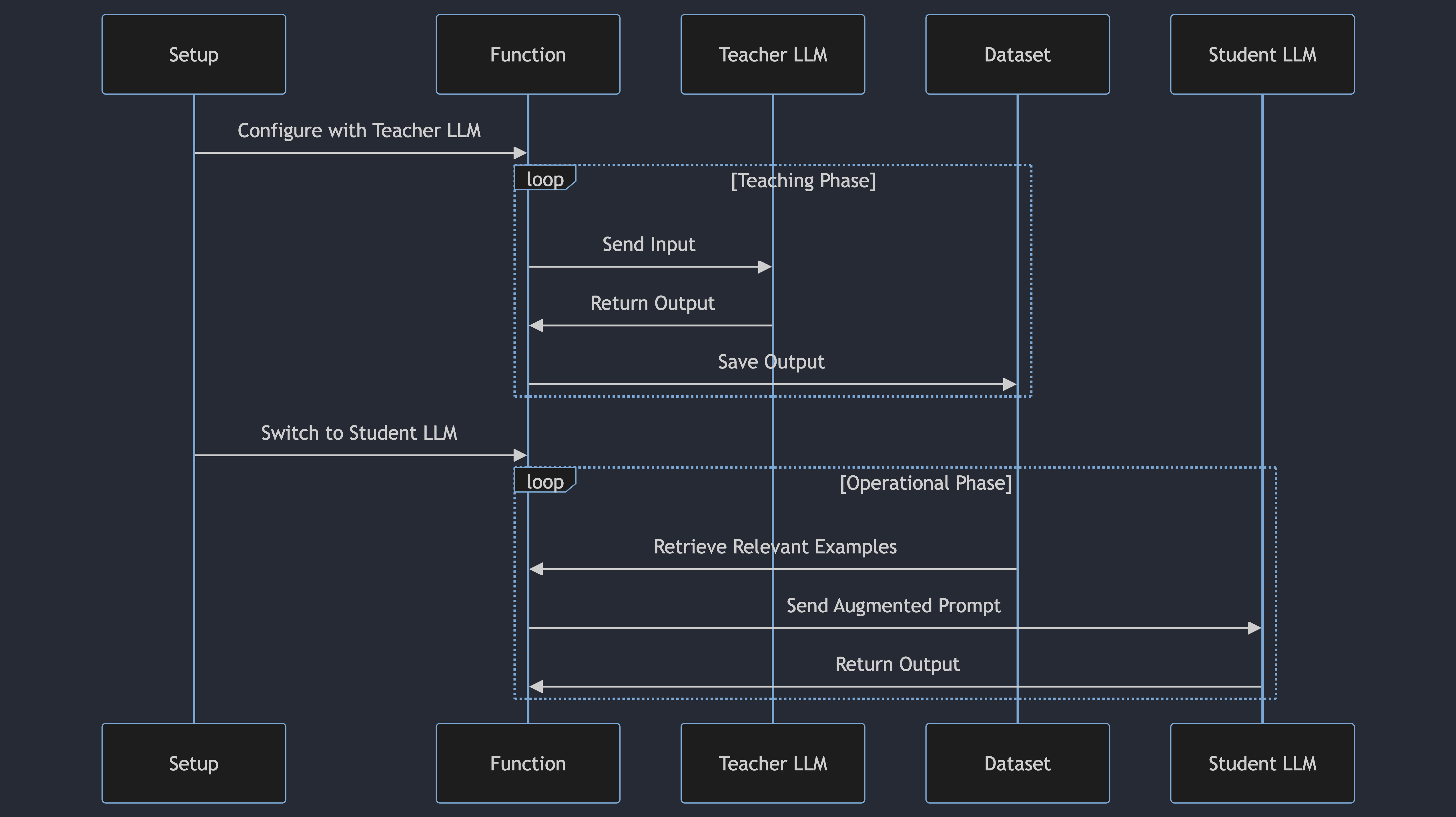
Let's enable few shot retrieval on our function and set the model to GPT-3.5 Turbo.
@fn(
model="openai/gpt3.5-turbo",
few_shot=True, # Enable few shot retrieval
few_shot_count=3, # Retrieve the 3 most relevant examples and add them to the prompt
)
async def predict_cot_with_examples(question: str) -> MathSolution:
"""Solves math problems"""
Every time the function is called, it will retrieve 3 semantically relevant examples from its dataset and append them to the prompt sent to the model. Pretty cool! We can now run our evaluation again
results_synthetic_examples = await evaluate(
testing, predict_cot_with_examples, max_concurrent_requests=100
)
calculate_pass_rate(results_synthetic_examples)
>>> Pass rate: 79.67% (between 77-80% depending on the runs)
Now we see some significant improvements! A relative 11% increase in accuracy compared to our original function with no examples.
In a few lines of code we have used a strong teacher model (Claude 3 Opus) to generate high quality examples for our student model (GPT-3.5 Turbo), with no human annotation, no prompt engineering, no heavy coding.
Few shot retrieval is an extremely powerful technique when dealing with use cases such as customer support bots - adding a relevant example for how to deal with refunds, or angry customers - or agent tool selection, where seeing similar examples of "correct" behavior can greatly improve the performance of the model. Think of it as on the fly fine tuning of the model on the task at hand :)
In the GSM8k benchmark, semantic similarity between the incoming problems and the right examples to chose probably isn't very high, so this is very much a worst case scenario (finding the best examples with random search yields even better results there!)
Conclusion
The LLM research community has leveraged synthetic data generation to dramatically improve the quality of datasets used to train and fine tune LLMs. It turns out that this technique is remarkably effective for us AI engineers as well. With LLM context windows getting larger and larger, one can imagine a future where we can add thousands of examples to a prompt to fine tune the model on the task at hand. Leveraging the teacher student pattern and Opper functions, we can easily start with a teacher model and seamlessly switch to a cheaper model in production, without changing our codebase.
Coupling a simple prompt ("Solves math problems"), chain-of-thought and examples greatly improves the performance of LLMs (from 25 to 80% on our benchmark), often bridging the gap between cheaper models and frontier ones. You don't need GPT-4 in production!