Getting the best out of LLMs, part 1
By Alexandre Pesant -
LLMs are impressive, but getting the best performance out of them isn't as straightforward as it seems. In this post we'll try to get GPT3.5 Turbo to solve some math problems, and see how we can improve its performance.
We'll work with the very popular GSM8k dataset. It consists of 8.5k high quality grade school math word problems. Each problem has a question and an answer with a step-by-step solution that shows the reasoning to arrive at the final answer.
Question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer:
Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72
Why GPT3.5 and not 4?
- The GSM8k dataset is now "too easy" for top models (or the dataset was simply part of their training data...)
- Cheaper/smaller/faster models are much more capable than we think :)
The dataset is available on huggingface, so we'll use the datasets library to download it.
from datasets import load_dataset
dataset = load_dataset("gsm8k", "main")
Evaluations are not optional!
We've spent decades working on software engineering techniques for making sure things work and keep on working, but somehow the moment LLMs came out we all seemed to forget about testing :)
But let's keep this rant for another blog post, and prepare our dataset so it's easy to evaluate.
# Splits the dataset into training and test sets based on the provided split ratio.
# Extracts the question, step-by-step solution (thoughts), and final answer for each problem.
def build_datasets(count: int = 100, split: float = 0.7):
train_count = int(count * split)
test_count = count - train_count
train_dataset = [dataset["train"][i] for i in range(train_count)]
test_dataset = [dataset["train"][i] for i in range(-test_count, 0)]
def parse_data(data):
parsed_data = []
for item in data:
question, full_answer = item["question"], item["answer"]
thoughts, _, answer = full_answer.partition("\n#### ")
parsed_data.append({"question": question, "thoughts": thoughts, "answer": answer or None})
return parsed_data
train_data = parse_data(train_dataset)
test_data = parse_data(test_dataset)
return train_data, test_data
Now we can build our datasets
# We take 1000 samples and split them into 70% training and 30% testing
training, testing = build_datasets(1000, 0.7)
We separate training and testing sets but will only look at the testing data in this post. We'll use the training data in a coming post.
Dealing with the LLM
We now have a series of test cases, with input and expected output. What we would love to have is a function that takes a question and returns the answer.
def predict(question: str) -> int:
We can probably write a prompt for achieving this:
You are an expert at solving math word problems. Given a question, provide a solution. Return the numerical value only
Then, we can append the question and parse the response, expecting an integer.
def predict(question: str) -> int:
prompt = "You are an expert at solving math word problems. Given a question, provide a solution. Return the numerical value only.\n Question: " + question
response = call_llm(prompt)
return int(response)
This isn't too bad, but as we'll see a bit later, it's simple because we're parsing one value.
Opper functions
The Opper SDKs are designed the make it easy to write code, not prompts.
The Python SDK provides the fn decorator, which automatically creates an Opper function from a Python function and its docstring.
from opperai import fn
@fn(model="openai/gpt3.5-turbo")
async def predict(question: str) -> int:
"""Solves math word problems"""
That's it! Now let's run our dataset through this function and see how well it performs. First let's define our evaluation function.
import asyncio
from tqdm.asyncio import tqdm_asyncio
# Evaluates a function on a test set
async def evaluate(test_set, function, max_concurrent_requests: int = 10):
semaphore = asyncio.Semaphore(max_concurrent_requests)
async def evaluate_item(item):
async with semaphore:
try:
answer_int = int(item["answer"].replace(",", ""))
result = await function(item["question"])
value = result if isinstance(result, int) else result.value
return {
"expected": item["answer"],
"got": value,
"question": item["question"],
"pass": answer_int == value,
"raw": result,
}
except Exception as e:
print(f"Exception: {e}")
return {
"expected": item["answer"],
"got": None,
"question": item["question"],
"pass": False,
"raw": str(e),
}
tasks = [evaluate_item(item) for item in test_set]
results = []
for f in tqdm_asyncio.as_completed(tasks):
result = await f
results.append(result)
return results
def calculate_pass_rate(results):
total = len(results)
passed = sum(1 for result in results if result["pass"])
pass_rate = (passed / total) * 100
print(f"Pass rate: {pass_rate:.2f}%")
return pass_rate
This function calls the Opper API for each item in the test set and compares the result to the expected value. The pass rate can then be calculated.
There is no other way to know that things work than to write evals in the LLM world!
Let's run our eval.
results= await evaluate(testing, predict, max_concurrent_requests=10)
calculate_pass_rate(results)
# Pass rate: 25.33%
~25% isn't great.
So naturally one might want to switch to shiny GPT-4. In the same setting GPT-4 gets 49%. Surely we can't go any higher? Let's see how far we can get with GPT3.5-turbo and equivalent models.
Chain-Of-Thought with JSON output
A popular and very effective technique for improving LLM performance is Chain-Of-Thought. The idea is to let the model progressively get to an answer by describing its reasoning. This greatly improves performance and should be the very first thing you do when trying to get better performance out of your applications!
Now if we go back to our "raw" text prompt, we could add a part about adding this chain-of-thought
You are an expert at solving math word problems. Given a question, provide your reasoning and a numerical solution. Return the numerical solution on a new line
Now comes the time to think about how to format and parse the response. This added complexity is why many don't incorporate Chain-of-Thought into their interaction with LLM.
But what if we treated the LLM as an external API that talks JSON only? Then we could call it like any other API and just get JSON back.
This is often achieved with function calling. Some LLM supports this mode where one can pass a JSON schema and get JSON back.
JSON (or any structured format like YAML) is the right abstraction above LLMs. It allows cleanly separating the step-by-step reasoning from the final answer. It also makes parsing the model's response much easier and less error-prone than dealing with raw text.
So let's update our Opper function to leverage Chain-Of-Thought, with the help of Pydantic
from pydantic import BaseModel, Field
class MathSolution(BaseModel):
"""A math solution with step-by-step reasoning and final answer"""
thoughts: str = Field(..., description="step-by-step solving of the problem")
value: int = Field(description="The final numerical answer to the math problem")
@fn(model="openai/gpt3.5-turbo")
async def predict_cot(question: str) -> MathSolution:
"""Solves math problems"""
We're now asking our model to return its step-by-step reasoning and then the value. The value must be an integer.
Let's rerun the same evaluations
results = await evaluate(testing, predict_cot, max_concurrent_requests=10)
calculate_pass_rate(results)
# Pass rate: 71.67%
71%, much better than 25%. And much better than GPT-4's 49%.
Let's look at one sample:
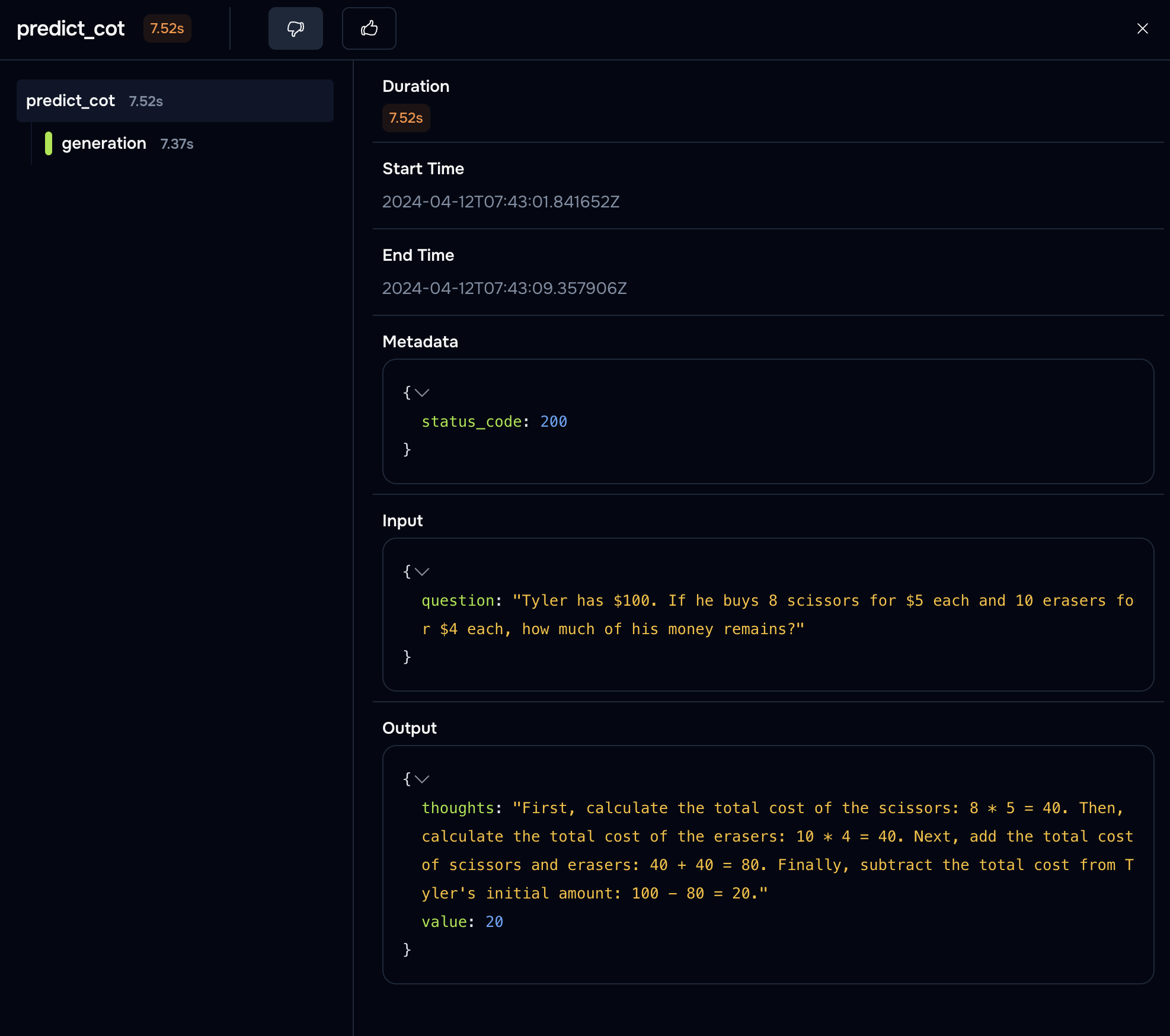
Looking at the model's reasoning can often help understand why it isn't getting the right answer.
It's not a silver bullet though, LLMs can be very confidently wrong :)
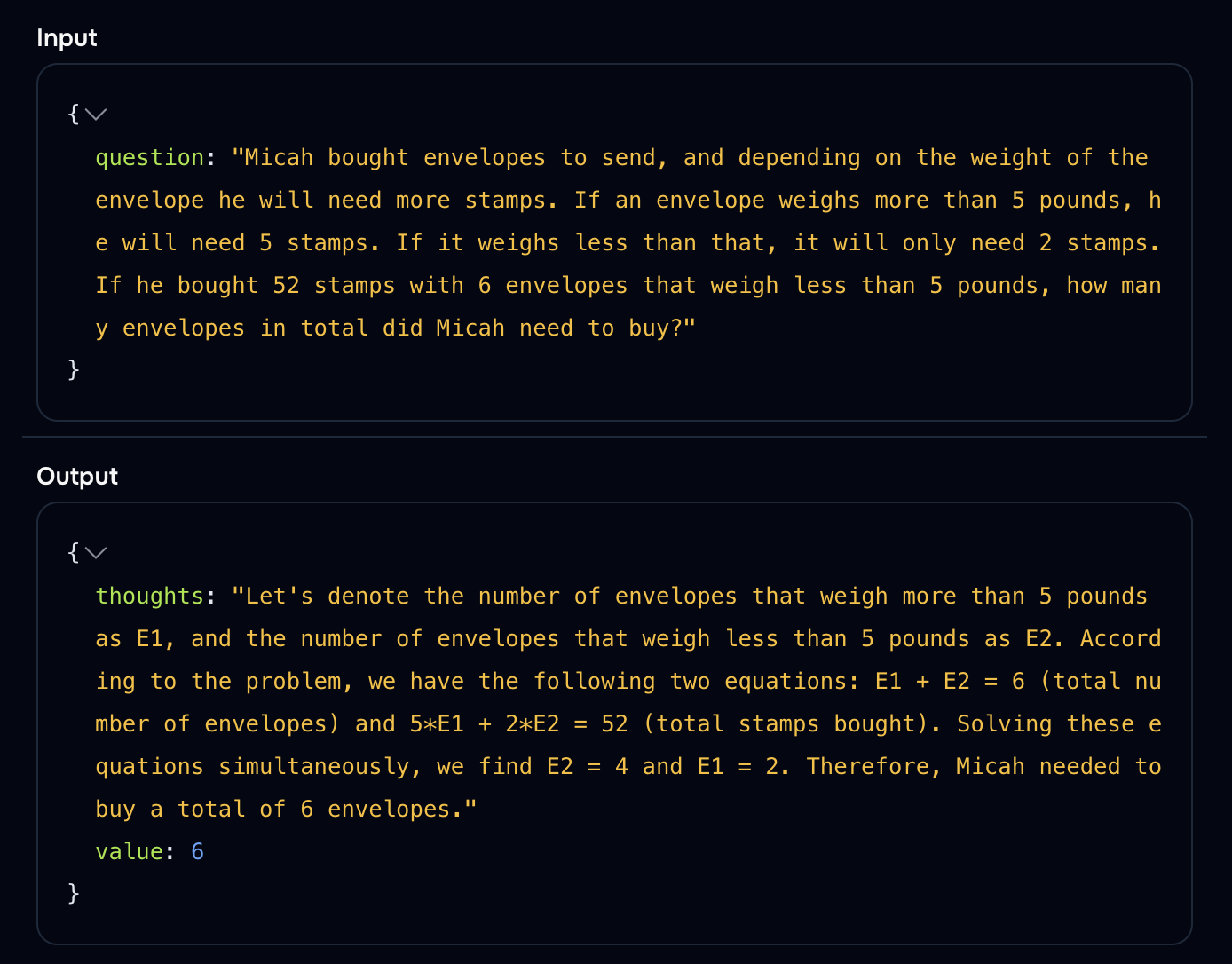
In this case we were expecting 14
Auto evaluations are the future
Opper can evaluate function calls automatically. Using an LLM as a judge isn't foolproof (yet), but it is a surprisingly effective way to get an idea of how well your model is doing. And models as judges are only going to get better :)
Let's look at the evaluation for the last sample:
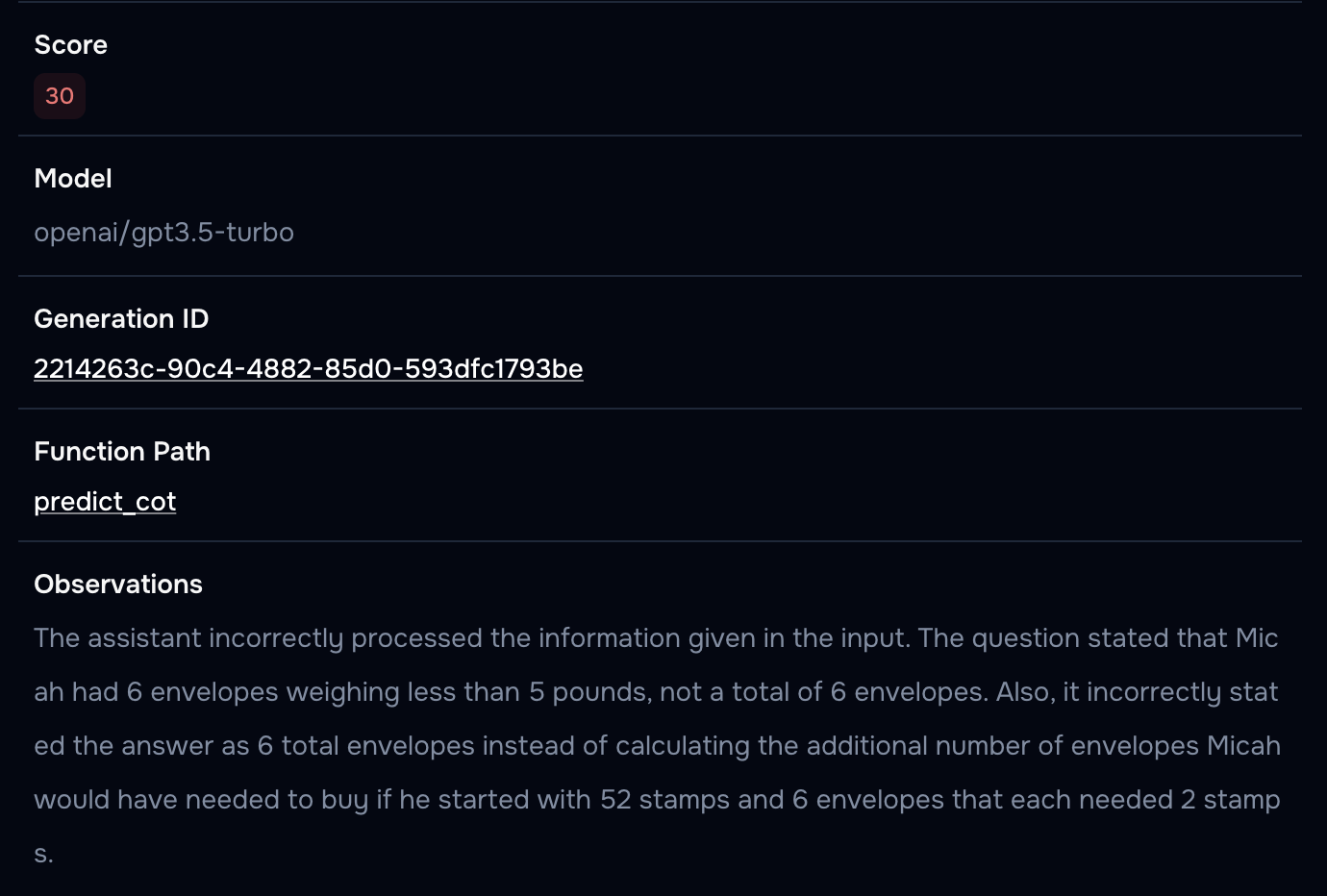
Opper scores this generation low and provides detailed observations about what went wrong. Pretty neat!
Some initial takeaways
- Think first about how you're going to measure that things are working. Opper automatic evaluations can help a lot with that, but for more complex applications you might need to write your own.
- Don't write prompts, write code! Structured generation, coupled with libraries like Pydantic are the way to go.
- If the models doesn't seem to reason well, try Chain-Of-Thought. It's almost always a guaranteed improvement.
- You don't always need the latest and greatest model. Smaller models can be very effective, and they're so much faster!
We can still do better than 71% accuracy though, let's see how in the next post!